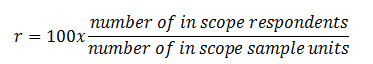Reference metadata describe statistical concepts and methodologies used for the collection and generation of data. They provide information on data quality and, since they are strongly content-oriented, assist users in interpreting the data. Reference metadata, unlike structural metadata, can be decoupled from the data.
Direzione Centrale per le Statistiche Sociali e il Welfare
Servizio Sistema integrato lavoro, istruzione e formazione
Statistical Production Department
Social Statistics and Welfare Directorate
Integrated labour, education and training Division
1.3. Contact name
Confidential because of GDPR
1.4. Contact person function
Confidential because of GDPR
1.5. Contact mail address
Istat Istituto Nazionale Di Statistica
Via Cesare Balbo, 16, 00184 Roma
1.6. Contact email address
Confidential because of GDPR
1.7. Contact phone number
Confidential because of GDPR
1.8. Contact fax number
Confidential because of GDPR
See below.
2.1. Data description
The LCS 2020 is based on the Council Regulation (EC) No 530/1999 concerning structural statistics on earnings and on labour costs and the Commission Regulation 1737/2005. It provides details on the level and structure of labour cost data, hours worked and hours paid.
The target population is composed by all the enterprises and institutions belonging to the Private and Public sectors with at least 10 employees in the NACE Rev. 2 sections B to S.
Since 2012 edition Italy has provided also data related to section O (even if the extension to this section is still considered optional).
2.2. Classification system
Statistical classification of economic activities in the European Community. NACE Rev. 2.
Nomenclature of Territorial Units for Statistics (NUTS) - NUTS 1 level.
Five size categories are distinguished: 10 to 49 employees, 50 to 249 employees, 250 to 499 employees, 500 to 999 employees and units having at least 1 000 employees.
2.3. Coverage - sector
Enterprises and institutions belonging to the Private and Public sectors with at least 10 employees in the NACE Rev. 2 sections B to S .
Since 2012 Italy has provided also data related to section O.
2.4. Statistical concepts and definitions
The variables provided are those required in the regulations according to the definitions stated there
2.5. Statistical unit
The sampling unit is the Economic Unit that is the Enterprise for the private sector and the Institution for the public sector. The observation unit, the one used to build up the aggregate data, is the territorial unit defined as the portion of economic unit in a Nuts1 region within the Economic Unit
2.6. Statistical population
The population covered in the LCS as requested by Regulation refers to the Enterprises and Institutions belonging to the Private and Public sectors with at least 10 employees in the NACE Rev. 2 sections B to S including O. The frame list, derived from the Italian Business Register (ASIA) referred to 2020, is composed by about 187,313 enterprises representing 9,198,453 employees as regard private sector and 17,803 institutions with 3,382,124 employees as regard public sector.
2.7. Reference area
Data are disseminated at national level and NUTS 1 level
2.8. Coverage - Time
The reference year is 2020
2.9. Base period
Not applicable
See below
3.1. Source data
Since LCS 2012 edition, the use of statistical registers built upon administrative data has gradually increased. The statistical processes for the Private and Public sectors are quite different. For the Private sector, data from a direct statistical survey was combined in all significant phases of the survey production process, with register data: the Annual Register of Individual Labour Costs (RACLI) data and the Business Register (ASIA) data. As for the public sector, data from the Labour Register (LR), from the Register of Public Institutions and data from administrative source have been used. In what follows, brief explanations of both are reported.
Registers and administrative data
The Labour Register is a statistical register containing information on employment and labour input, wages, contributions and income. It is the heart of labour statistics and its development in recent years has greatly enhanced the labour statistics either due to the production of output directly or by constituting a coordination framework able to provide much greater coherence to the entire system for labour statistics.
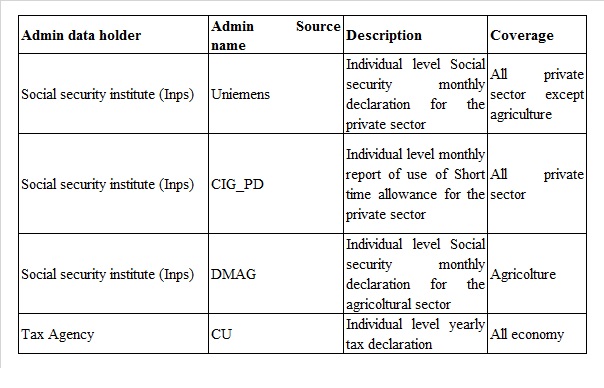
The setting up of such a register in Italy is extremely demanding as it is based on a plurality of administrative sources (see tables 3.1.1 and 3.1.2). The backbone of the system are the Social Security Institute (INPS) data and among them the UniEmens declarations. Moreover, the tax declarations, especially those submitted by the economic units for their workers (the new CU declarations) will be introduced both to guarantee a better coverage in term of units (e.g. is needed to ensure the coverage of not dependent jobs under an income threshold) and additional variables (e.g. those related to taxation and net income).
For the production of LCS 2020 two main registers (which can be viewed as subsets of the whole LR) have been used: for the private sector RACLI (which was also used for the 2016 edition of LCS) and for the public sector LR-public.
Table 3.1.1. Main sources for RACLI register
Table 3.1.2. Main sources for LR-public register
The statistical process for the Private sector
The survey for the private sector is a mixed register-sample survey process.
In fact, thanks to the availability of the RACLI register, LCS 2020 in the wake of what has already been done for the LCS 2016 an 2012 edition, has been designed introducing several solutions to allow a mutual integration between survey and register. In this approach, the register data assists the survey in some phases of the process, and the survey’s results can be used to check the register data and provide details not available in the Register.
The design of the process, therefore, had to take into account the timing of the availability of the register. Following the scheduled availability of Social Security data, the RACLI register is available as a provisional version in the autumn of year t+1 and, as a final version, in the spring of year t+2. So the provisional version was used for sampling, for prefilling the variables of the questionnaire and for checks during the data collection phase, while the final version was used for the post collection editing and imputation, including the imputation of non-responses, for calibration of the survey weights to known totals and for validation of the data. Moreover, the final data are used to evaluate comparatively the variables available in the register and those collected through the survey particularly to evaluate definitional issues.
This approach was guided, since LCS 2012 edition, by two main principles: the reduction in response burden: both the sample and the questionnaire were designed to obtain this objective, and the increase in the data quality, as it will be seen in the following paragraphs.
The frame list, derived from the Italian Business Register (ASIA) referred to 2020, is composed by 187,313 enterprises representing 9,198,453 employees. The final sample is composed by 24,521 enterprises.
The sampled enterprises had to provide data for the whole unit, through a web based questionnaire (CAWI) with some built in checks (first level checks). In a subsequent step the data are divided for each enterprise in the areas (NUTS1) in which the employees were localized with the help of information contained in the RACLI register. Thus the sampling unit is the enterprise and the observation unit (analysis unit) is the portion of enterprise comprised in one nuts1 area.
The statistical process for the Public sector
The statistical process of the public sector is entirely Register based. It is founded on two statistical registers, the Labour Register (LR) and the Register of Public Institutions and an administrative source, the Annual Account of the Ministry of Economy and Finance.
The frame list is derived from the institutions of the Register of Public institutions and the Labour Register. The final list is composed by 17,803 institutions with 3,382,124 employees.
Data sources
The statistical unit of the Labour Register is the job position, that is, for the employees, the employment relationship between an economic unit (the employer) and an individual (the worker) also identified by an activation date.
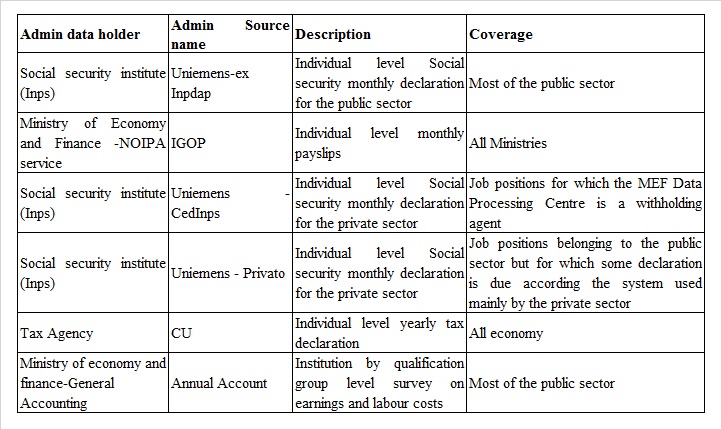
The LR for the public sector is fed by 5 main administrative sources: 1) the individual social contribution declarations that every month public institutions transmit to INPS through the PosPa List section of the Uniemens (ex-Inpdap source); 2) the individual monthly payslips compiled by the NOIPA system of the Ministry of Economy and Finance (MEF) for the administrations that have joined the system (IGOP source); the contribution declarations that the economic units of the public sector transmit to the INPS through the section Lista Poslav of the Uniemens divided into those produced: 3) by the MEF Data Processing Centre, as a withholding agent, for employees, mainly temporary, of some ministries (source CedInps) and 4) from all other withholding agents of the public perimeter that for administrative reasons use the section Poslav List as private sector enterprises (source Private); 5) the yearly tax declarations (source CU).
These sources, after data treatments aimed at eliminating duplications and harmonizing them, are integrated into a single database, with monthly information for each job position. In this phase an important role is played by the information taken from the Matrix of links between administrative units and institutional units produced within the operations for the Register of Public Institutions.
At this level the Register contains information on the characteristics of the job position (national collective agreement –NCA-, job title, type of working time, percentage of part-time, type of contract), on the labour input, measured as the average number of monthly positions, and the number of hours paid net of overtime. The number of overtime hours is estimated a) for the job positions covered by the IGOP source, using the wages for overtime hours, contained in this source, and the average hourly overtime rates from the collective agreements and the Annual Account and b) for the rest of the population of job positions with a massive imputation method that uses information from the Labour Force Survey.
The Annual Account is a takes-all survey carried out by the Ministry of Economics and Finance - General Accounting (RGS) to measure the personnel costs of public institutions. The data of the Annual Accounts, have been suitably studied, analyzed, and reclassified to produce data that fit the definitions of Labour Cost Survey regulation (Commission Implementing Regulation 1737/2005). Finally, for a very limited number of units the data were collected through the questionnaire built for the private sector. These are units that only recently passed from the population belonging to the private sector (as defined by the Business Register Asia) to the one belonging to the public sector and in particular in the list S13. These units are not yet covered by the Annual Account and are broadly similar, in many respects, to private sector units.
Data Processing
The data processing for the public sector consists in the construction of a takes-all database on public sector units with the variables required by the LCS regulation. The processing steps can be summarized as follows. First, LR data on labour inputs and paid hours, broken down by type of working time, and wages are aggregated by legal unit, NCA code, job title code. The second phase is to group from the Annual Account data on hours of absence, wages, contributions and other labour costs (according to the LCS classification) by institutional unit, NCA code, job title code. In the third stage, the information of this second database is used to impute the LCS missing variables in the first database, at legal unit, NCA code, job title code. In the fourth phase, the data are aggregated at the legal unit level and the classification variables, such as the economic activity and the territorial location, derived from the Register of Public Institutions and the Matrix of links between administrative units and institutional units, are added to the data. At this stage, in relation to the Ministry of Education, University and Research (MIUR), Educational and Training Institutions are classified in Section P of the NACE (Education), while the rest of the Ministry is classified in Section O (Public Administration and Defence; Compulsory Social Insurance). In the last step, the data is subject to editing and imputation procedures that adopt the same techniques and software used for private sector data.
3.2. Frequency of data collection
The survey is carried out every four years.
3.3. Data collection
The data collection phase, as mentioned, has involved only the private sector, and consists of a very articulated survey process, managed through a detailed calendar, built around a Centralized data collection System the “Business statistical portal” and a dedicated Contact Center (CC) for inbound and outbound services involved to provide assistance to respondent units.
The Business Statistical Portal operational since 2014, is a single entry point for Web-based data collection from enterprises which allows to organize the business surveys, optimizing the management and the control of the entire data collection process. The Portal is structurally designed in different specific areas and all the instruments useful for surveys are available inside the same environment. The portal covers the main functions of the entire data collection process: the Survey unit list management, the data collection management, the questionnaire, the communication facilities.
The data have been gathered through a Web-based questionnaire (CAWI ), the enterprises involved in the survey have to access to the questionnaire by portal through user IDs and passwords. Respondents can receive assistance in compiling the questionnaire by toll-free number and other asynchronous channels managed by the CC operators. In order to allow the operators to manage opportunely the assistance, Istat experts carried out specific training on both technical and thematic aspects of the survey. Furthermore, CC operators have been provided with detailed FAQs and instruction manual to be used during the contact with the respondents. In particular, during the inbound service, the CC provides assistance to compilers in the registration and navigation of statistical Portal, as well as on the general questions concerning the survey's content and on the most frequent issues. The instances more specific and complex not solvable by the CC are forwarded to Istat subject matter experts through a specific tool - the shared agenda. An outbound service was carried out before the end of the data collection period to re-contact the most relevant non-respondent units.
The questionnaire design
Due to the availability of information form the Racli register, since 2012 the questionnaire has been largely simplified respect to previous editions. The starting point in questionnaire design was to identify the variables in the register that fulfill perfectly the LCS definitions and the ones that are the core component to calculate what is required. Information available from the register and not necessary for checking purposes have been removed from the questionnaire; furthermore, in order to build a questionnaire with a strong link with the register, the number of employees - full time and part time - and the annual social security wage were prefilled, whit the RACLI register data. The respondents had to fill the wage components breaking down this top variable into its sub-components and had the opportunity to give a different response if necessary, correcting the prefilled- values . This approach allows simplifying the questionnaire thus reducing the volume of data to be collected and the burden on respondents and set up procedures of E&I and calibration that exploit the information of the Register as much as possible.
To reduce measurement errors, in addition to traditional post-data-collection editing, the web-based questionnaire (CAWI) had built in checks (first level checks) that were tested before the data collection period. The questionnaire could not be submitted before all the values provided were congruent with the built in checks. More in detail, error messages accompanied by a red icon and an item number indicated an incorrect value. The icon was displayed directly near either the incorrect item and clicking on it a message explaining the kind of error appears near the incorrect value. An orange icon with an exclamation mark was used to signify soft errors. This kind of edits only notify users that an item should be assessed for its adequacy. In this case, the respondent could confirm or correct the value. The questionnaire could be submitted only if all errors with red icons were solved. The edit failures were shown at the end of the questionnaire After correcting also any edit, the list would reappear without the edit just corrected.
In the editing and imputation procedures, the RACLI data are used in several ways. In the data of respondents they have been used for: the edit rules that imply the consistency between a core component (from the register) and a sub-component (from the survey); the formation of more homogenous edit groups; and, providing the matching variables in the minimum distance imputation.
For the non respondents, the register variables represent the basis of the questionnaire.
For all these reasons the private sector survey can be defined an “administrative data assisted survey”.
For details on measurement errors, see concept 6.3.2.
The public sector data are total data since only admin based.
Before the results were sent to Eurostat, validations of the figures were done, at an aggregate level (section and division levels of NACE Rev.2, size classes and regions at the NUTS-1 level), using the recommended checks (on relationship between variables, consistency checks and cross checks between tables).
Comparisons are made with previous years estimates to validate the results. In addition, Eurostat also carries out validation checks on data transmitted by countries.
3.5. Data compilation
At the end of the statistical process the RACLI register has also been used to reweight the sample. The calibration variables are the number of employees, the social security wage and the number of hours paid. This has allowed to calculate weights that produce estimates aligned with the final version of the register, while at the time of the sampling selection, only a provisional version of the RACLI register was available.
3.6. Adjustment
Not applicable
see below
4.1. Quality assurance
LCS is based on the standard Istat systematic approach to quality following the International and European standards. Istat reference framework for quality relies on the European Statistics Code of Practice, adopted in 2005, revised in 2011 and in November 2017 . The Data Quality Assessment Framework, developed by the International Monetary Fund, also represents an important reference, especially for economic statistics and for National Accounts. With the aim of strengthening the commitment to quality and to better coordinate the many activities already underway in the institute, in September 2020 the Quality Committee was reconstituted, with the objective of overseeing all quality initiatives in Istat (this body had already been active from 2010 to 2016).
Quality monitoring is based on the analyses of standard quality indicators, also managed in the Information System for the Quality of Statistical Processes (SIQual). Both qualitative information and quality indicators related to each single phase of the production process are managed.
Quality pilots, trained in process documentation and quality evaluation, are in charge of updating information and calculating standard quality indicators at process level. Starting from 2016, all ESS quality reports published at International level are published in SIQual system, in particular under the section Labour and Wages there can be found the Structure of Earnings survey ones (more details at the link: https://siqual.istat.it/SIQual/visualizza.do?id=5000079&language=UK)
The overall quality of the Italian LCS can be considered good.
See below
5.1. Relevance - User Needs
The main users of the Labour Cost Survey data in Italy and abroad can be classified as follows:
-National (internal) users:
units of National Statistical Institute (Istat);
analysts, including researchers from public and private institutions and from universities;
mass media;
lecturers, students, independent research institutions and researchers.
-International users:
Eurostat, International Labour Organisation, International Monetary Fund, United Nations Economic Commission for Europe.
5.2. Relevance - User Satisfaction
No direct assessment of user needs and user satisfaction has been carried in recent times.
5.3. Completeness
All the mandatory variables required by Eurostat regulations were provided.
5.3.1. Data completeness - rate
100%
See below
6.1. Accuracy - overall
not provided
6.2. Sampling error
Sampling design of the LCS survey for the private sector is a one stage stratified random sampling. LCS sample strata are defined by the combination of the modality of the characters Nace Rev.2 divisions, 5 size classes (10- 49 employees, 50-249,250-499,500-999, 1000 +) and 5 Nuts 1 level areas.
The enterprises belonging to strata with over 250 employees or in strata with few units in the sample have been sampled with a probability equal to 1 for a total of 647 take all strata. As for the remaining 1,395 strata, the number of units to be selected in each stratum is defined as a solution of a linear integer problem (Bethel, 1989). In particular, the minimum sample size is determined in order to ensure that the variance of sampling estimates of the variable of interest in each domain does not exceed a given threshold, in terms of coefficient of variation. The driving variables used for sample allocation are Number of employees, Wages bill, whose mean and variance are estimated in each strata by data from the provisional release of the RACLI Register (available at the time of sampling) aggregated at the level of enterprises. Given the way in which different registers are built together, this sampling frame is equivalent to the Business Register for either the list of the enterprises and the number of employees in each enterprise. According to the final allocation, 24,521 enterprises (units) have been included in the sample from a target population of 187,313. Although the provisional version of Racli register is usually very close to the final one, there can be coverage errors and estimation biases. For this reason and moreover to obtain a perfect consistency between some of the estimates of the survey and those of the register the sampling weight are calibrated to known population totals of selected auxiliary variables derived by the final version of the Racli register. The selected calibration variables are the number of employees, the wages bill and the number of hours paid.
Regarding for the public sector, as above mentioned, data for all the units belonging to the frame list is obtained through registers and existent data sources.
6.2.1. Sampling error - indicators
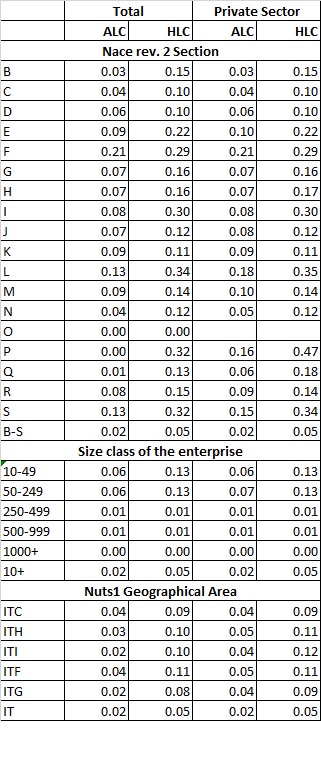
Table 6.2.1.1 reports the percentual coefficient of variation (CV) of Annual labour costs (code D) and Hourly Labour Costs (code D/B1). For the country as a whole the CV is 0.02% for the first variable and 0.05% for the second.
Table 6.2.1.1 Coefficient of variation (%) for Annual Labour Costs (ALC) and Hourly Labour Costs (HLC)
The target population on which the survey has been designed is defined by the private businesses and institutions and public institutions belonging to the section B-S Nace Rev. 2. including the section O. For the private sector, the provisional RACLI register referred to 2020 has been used in sampling while to reweight the sample at the end of the statistical process the final frame version was used. Therefore for the type of statistical process used data hasn’t coverage error in most sectors and very low coverage rates in the remaining ones.
As for the public sector data are register based, there is no list or coverage errors by definition.
6.3.1.1. Over-coverage - rate
For the type of statistical process used it is considered that the data has no over-coverage
6.3.1.2. Common units - proportion
not available
6.3.2. Measurement error
Measurement errors are defined as errors occurring at data collection time, while processing errors occur in post-data-collection processes.
While little information is gathered on processing errors some considerations can be drawn on measurement errors. First, we define measurement errors those considered such by our Editing and Imputation procedures. As above sketched, for the public sector, all variables have been derived from registers directly or through estimation methods.
In this section thus the focus is on the private sector. For the private sector most of the variables have been derived from the RACLI register. Some of them have been pre filled in the questionnaire and could have been modified by the respondent. The variables not available in the registers have been moreover added to the questionnaire.
All the variables, even those derived from the register, have then been passed to the editing and imputation procedures and edited when considered incorrect. Then the variables requested from the Regulation were obtained by adding and/or subtracting items. This implies that some of the target variables, those on wages and salaries, social contribution, employees and hours paid, are composed from a part derived from the register and a part derived from the questionnaire.
The result of these procedures is that there are very different item imputation rates among the variables. In particular, the variables with the highest imputation rates are those completely not available in the register or those composed partially from the register and partially through the survey, since it is on them that the imputation of non respondents impact. However for the second group, since the part not available from the register is very small compared to the total, the imputation usually change the requested variable only slightly.
In detail, in editing and imputation procedures used for the private sector the RACLI data play an important role. The private sector survey can be defined as an “Admin data assisted survey”. RACLI data are used in several ways, limited to the respondents:
- to supply the values applied in the edit rules to guarantee the consistency between the core component (from the register) and a sub-component (from the survey),
- to build homogeneous edit groups,
- to provide the matching variables in the minimum distance donor imputation.
As concern the first item, the comparison between survey data and RACLI data represents the instrument for detecting and possibly correcting the former through deterministic rules. Whenever the prefilled values were changed by the respondents a first deterministic procedure is used to verify and correct the data against the RACLI values. In particular the procedure assesses:
1) the accuracy of the employees (full-time, part-time, apprentice), through the RACLI employees,
2) the precision of the quantitative variables as wages and salaries, social contribution, hours paid drawn from the survey and to quantify the possibly divergence. The procedure uses as a cut-off measure the calculated differences between the values of the same variable taken from the survey data and RACLI data divided by their average, and in case the survey data are outside the chosen limits (cut-off) Admin data replaces survey data, and sub-components are recalculated, taking care to preserve the existing proportion between the survey core variables and their sub-components.
In most cases the data provided by the enterprise is changed back to the admin data value.
A second probabilistic procedure, built around the BANFF system (Statistics Canada) is used for automated editing and imputation of quantitative data on wages and salaries and working time.
To take into account critical differences among the hours paid and wages and salaries, the main edit rules into the system were written distinguishing for specific group of main activities of the enterprises (Education, Arts and entertainment, Transportation maritime, Tourism, Cinema, Television, etc.) respect to the others, and the imputation is run within groups of enterprises with the same hours paid, number of employees (full-time, part-time, apprentice), wages and salaries and economic activity. In general, the main edit rules check for errors in the composition of the main variables and in the ratio between monetary values and hours, and hours and number of employees.
The probabilistic procedure has been carried on three step: firstly, focusing on hours paid and wages and salaries; secondly, focusing on other variables (such as Statutory social-security contributions that includes TFR, Vocational training costs paid by the employer) and finally, focusing on all variables only for apprentices.
In these steps the variable more affected by editing, among the sub-items of the labour costs, was wages and salaries for days not worked. A large share of firms reported zero values or values implausibly low. While a part of these firms may have misunderstood the question, the main reason seems to be that this information is absent in their information systems, due to the fact that wages are fixed on a monthly basis and are not influenced by days not worked for holidays and leaves. When the value was zero, missing or implausibly low it was imputed with a value obtained by multiplying the reported number of hours not worked but paid for holidays and leaves for the value of a normal worked hour. This is in turn obtained by dividing the direct remuneration paid in each pay period (excluding wages for overtime) by the number of hours worked (minus the overtime). These peculiarities involved also the same variable on Apprentices.
Among the variables more affected by editing there are those related to social contributions. In fact, the ratio of TFR to wages and salaries and, hence, the ratio of social contributions (which includes TFR) to wages and salaries were particularly affected by editing. This is due to the fact that employers bear the cost of TFR also in case the workers are in short-time working allowance when the wage guarantee allowance and other social security contributions are borne by social security institutions. Therefore, the increase in social contributions via TFR has led to the failure of the proportionality rule on wages and salaries.
In this framework, the records for thenon respondent enterprises have been compiled on one side from the variables available from the registers RACLI and on the other with values imputed through minimum distance donor methods. All this procedure has been applied to the questionnaire scheme.
As the set of core information and the extra information from the subsample (respondents of private sector) have already been edited and imputed and that no consistency edits need to be applied, they are so used to estimate the not respondents. On 24,521 total observations of private sector, the share of 38% represents the non respondents. The availability of the set of core information (wages and salaries, employees, hours paid, in the year) for the entire sample drawn from RACLI lets to perform a massive imputation on the non respondents to obtain the extra components.
For each group of enterprises with the same economic activity, the share between the core variables and their components measured on respondents are donated to the non respondents with a massive imputation from the valid observation that is most similar to it according to matching fields (wages and salaries, employees with full-time, part-time, and apprentice work arrangement, hours paid for full-timer, part-timer, and apprentices in the year).
6.3.3. Non response error
For what has been said before non response errors affect only process for the private sector. Since some of variables, those derived from the register, are available for the entire sample, the unit non response rate assume the meaning of percentage of non respondents to the direct survey not that of units whose all values must be imputed.
6.3.3.1. Unit non-response - rate
Unit response rates are calculated, following the indication of regulation n. 698/2006 as follows.
The units in the sample that are deemed in scope are those belonging to the frame 2020. In other terms, the sampling units that according to ASIA 2020 are not in the target population are considered out of scope.
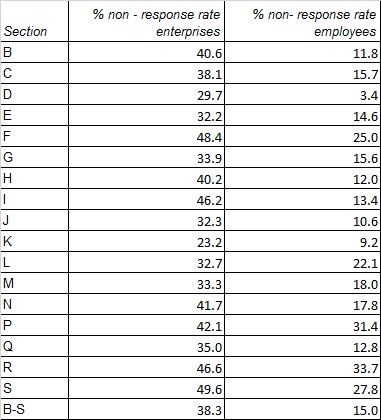
The non-response rate in terms of enterprises is 38,3%, while in terms of sampled employees is 15,0%.
The results are shown in Table 6.3.3.1.1 below.
It has been considered a respondent an enterprise whose questionnaire has been successfully “sent” through the web application and has passed the formal check rules built in the electronic form.
Table 6.3.3.1.1 - Private sector: non-response rates in terms of enterprises and employees
Since the questionnaire could not be sent if only single variable was not filled in, there are no item non response for the variable Annual Labour costs, code D in LCS classification.
6.3.4. Processing error
Little information is gathered on processing errors.
6.3.4.1. Imputation - rate
The Item imputation rate is calculated as the ratio of values imputed for a specific variable over the total number of values for that variable. For the variable Annual Labour costs, code D in LCS classification, it is 39.4%.
This total figure is composed by 14.9% changes of the reported figure from a positive value to another, and 24.5% deriving from the total non-responses which, as said before, have been imputed. The value of changes depends on the two factors; on one hand, that reported values have been compared with the benchmark values derived from the social security RACLI register and implausible differences have been considered errors in the reported data. In other terms the values substituted have been considered much closer to reality than reported values; on the other hand, that changes in any components of the total labour costs may affect the number of changes in the total.
Overall imputation rate
The overall imputation rate is calculated as the ratio of values imputed for any LCS mandatory variable over the total values for mandatory variables.
It is 31.4% of which 5.9% are changes of the figure provided from a positive value to another, 1% changes from a zero o blank value to a positive value and 24.5% deriving from the total non-responses.
6.3.5. Model assumption error
Model assumption errors may affect editing and imputation rules. For the imputation of unit non responses, the main variables (number of employees, number of hours paid -except overtime and total wages) have been drawn from the RACLI register. The remaining variables have been imputed according to a minimum distance donor imputation rule.
6.4. Seasonal adjustment
Not applicable
6.5. Data revision - policy
not available
6.6. Data revision - practice
not available
6.6.1. Data revision - average size
not available
See below
7.1. Timeliness
The data appeared for the first time on Eurostat database on December 1st 2022. Thus the length of time between the end of the reference year (2020) and the first publication of data is of 23 months.
7.1.1. Time lag - first result
not available
7.1.2. Time lag - final result
not available
7.2. Punctuality
As for the EU deadlines Italy delivered the data at the end of June 2020 respecting the Regulation deadline (30 June 2020). However, after Eurostat data validation, a further data transmission has been necessary due to review in a data subset.
As concerning the fieldwork, data collection period was scheduled from November 29th 2021, to March 25th 2022. However, it became necessary postposing the deadline, to obtain an improvement in response rate. The data collection officially closed on April 28th, so data collection lasted for five months. During this period, non-respondent units received several reminders, both by ordinary and certificated e–mail.
7.2.1. Punctuality - delivery and publication
not provided
See below
8.1. Comparability - geographical
The LCS 2020 complies with the standard set up on the Council Regulation (EC) No 530/1999 concerning structural statistics on earnings and on labour costs and with the definitions of variables adopted in the Commission Regulation 1737/2005.
8.1.1. Asymmetry for mirror flow statistics - coefficient
not available
8.2. Comparability - over time
The LCS 2020 is broadly comparable with the previous edition of LCS (2016) for what concerns the main aggregates. The main, methodological and technical aspects have not been changed, nevertheless some indicators must be compared with a particular caution considering the events characterizing labour market in the pandemic year. Furthermore, some choices of the E&I and estimation have been made to allow a better mutual integration between survey data and administrative . For these reasons some indicators may have problems of comparability (like hourly indicators, hours per capita.) due to differences in measuring variables between register and survey (for example for the variables “hours paid” and “hours worked”). Another area in which there might be problems of comparability is the public sector: as for the LCS 2016 edition the entire process is based on administrative data, but in this edition the sources used are partially different from the previous edition. Moreover some parameters used for the estimation of not available variables have been revised compared to the previous edition. Furthermore as regard sector P, some methodological changes caused the increasing of the estimation of hours worked. In the LCS 2020 edition, in fact, the process improves the estimation hours worked of Education sector by adding the hours of not frontal teaching to the contractual hours, and using a new method of estimating overtime hours.
8.2.1. Length of comparable time series
-
8.3. Coherence - cross domain
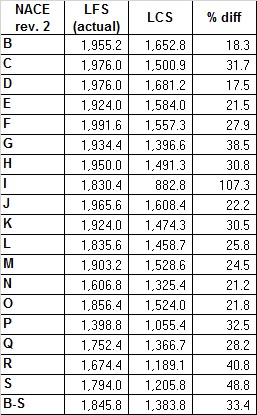
Hours worked per employee: LFS vs LCS
Table 8.3.1 reports the difference between the average number of usual weekly hours of work in main job annualized estimated by the LFS and the average number of hours worked in the LCS (codes B1/A1). Although the concepts are very similar the difference in the levels is striking, averaging 33,4 % in the B-S sectors. Several factors may be at the root of these differences. A first main factor is that LCS produces figures on the worked hours paid by the enterprises, while LFS results are related to the number of hours actually worked by the individuals (workers) during the reference week which include all hours including extra hours, either paid or unpaid (that is, this includes all hours worked including overtime, regardless of whether it was paid). In other terms while the LCS measurement, being a survey direct to employers, is unable to measures hours worked but not paid. LFS is likely to catch these irregular hours since the question is posed to the employees. On the other side it is known that LFS may underestimate the hours of absence from work (for holidays, leaves, sickness etc..) (see the work of the Task force).
Table 8.3.1 - Actual Hours worked in LFS vs Number of hours worked in LCS. Year 2020
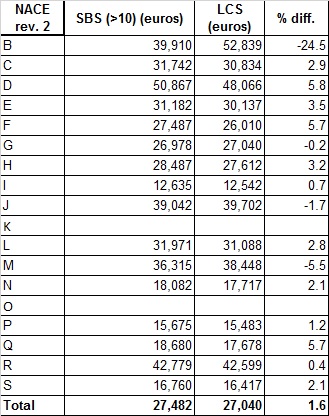
Wages and salaries per employee: SBS vs LCS
Table 8.3.2 compares the wages and salaries per employee as measured in SBS statistics and the one measured in LCS (codes D11/A1). To perform a more meaningful analysis the comparison is restricted to the target population in common between the two statistics: enterprises in the private sector with at least 10 employees with the exception of sections K and O. The two sources measurement systems are very different in some aspects but have also similarities. LCS, for the private sector, is a direct sample survey, although edited and integrated with social security data. The estimates of employees are calibrated to the business register values. SBS source data is a sample survey (PMI) for the enterprises with less than 250 persons employed and a total survey (SCI) for the enterprises with 250 and more persons employed. The administrative source used in the process of data production are the following: Financial statement of the corporate enterprises from Chambers of Commerce; ISA (synthetic indices of reliability) data and Tax return data from the Fiscal authority; Social security data. Personnel costs and other main economic variables (value added, etc.) are directly available from the administrative sources. The number of employees are extracted from the Business Register. The administrative sources are available at micro level and are used both as basic data and for imputation in case of non-response.
With the exception of section B the differences between the two sources are quite limited, averaging 1.6% in the total. This is due to the fact that the concepts of wages and salaries in the two statistics should be quite close. It is not easy to say how much close since, while the official definition of wages and salaries in LCS is very detailed, the one in SBS is more uncertain.
Table 8.3.2 - Wages and salaries per employee in SBS vs LCS. Only private sector-Enterprises with at least 10 employees. Year 2020
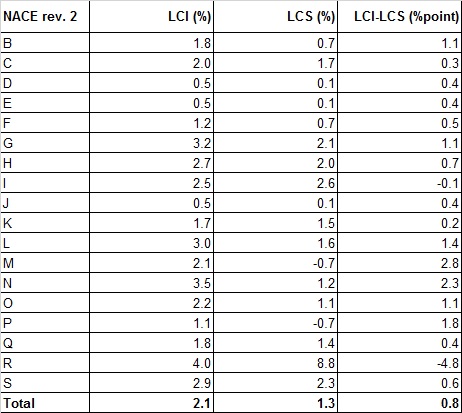
Hourly labour costs growth rates: LCI vs LCS
The Annex of the Commission Regulation (EC) No 698/2006 implementing Council Regulation (EC) No 530/1999 as regards quality evaluation of structural statistics on labour costs and earnings states that a comparison must be made between the average annual growth rates of the variable hourly labour costs (codes D1, D2, D3 and D4 minus D5, divided by the value of code B1) and the average annual growth rate of the unadjusted LCI. Table 8.3.3 shows the difference in the average annual growth rates between 2020 and 2016 of hourly labour costs between the unadjusted LCI (of December 2022 release) and LCS. Empirically in the total the difference amount to 0.8 percentage points. However this average hides quite relevant differences between single sections. Here the difference in definitions should not be relevant. In fact the circumstance that labour costs (code D=D1+D2+D3+D4-D5) in LCS includes items that are not included in the labour costs for LCI, where the total labour costs is equal to D1+D4-D5, should play a minor role in the difference of the growth rate due to the tiny share of vocational training costs, D2, and other expenditure, D3, on the total labour costs in Italy. Many factors here can be at the base of the differences. An impact on the differences may be due to the different coverage. LCI cover enterprises and institutions of every size, while LCS is restricted to those over 10 employees. The impact can be very relevant in sectors where the share of small units is large, like in Construction (section F), Wholesale and retail trade (section G), Accommodation and food services (section I), Real estate (section L), Professional, scientific and technical activities (section M), Arts, sport and recreation (section R) and Other service activities (section S). Furthermore, it’s worth noticing that LCI for sections O to S is mainly based on National Accounts figures drawn from an ad-hoc procedure that provides both the labour cost variables and the hours worked, for regular workers, introducing possible differences in definition. For sector P only, the divergence in the annual growth rate 2020/2016 is also due to methodological changes affecting the estimation of hours worked. In the LCS 2020 edition, in fact, the process improves the hours worked of Education sector by adding the hours of not frontal teaching to the contractual hours, and using a new method of estimating overtime hours. These changes caused the increasing of hours worked in the period, and the growth rate of the hourly indicators is affected by that spurious factor.
Table 8.3.3 – Average annual growth rate of hourly labour costs (year 2016-2020): LCI vs LCS
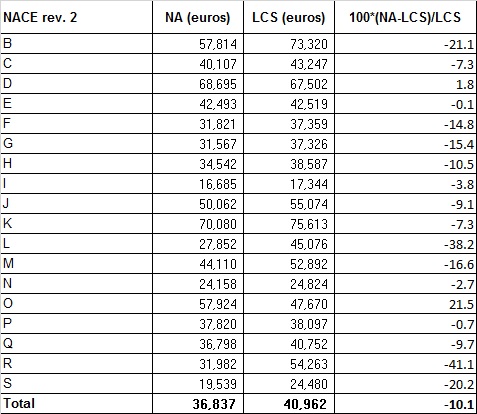
The Annex of the Commission Regulation (EC) No 698/2006 implementing Council Regulation (EC) No 530/1999 as regards quality evaluation of structural statistics on labour costs and earnings states that a comparison must be made between the LCS and the NA compensation of employees, expressed per employee (code D1/A1). In this paragraph the results of the comparison based on figures drawn from the release of September 2022 for NA and the release of December 2022 for LCS 2020 are presented. The NA data used in the comparison are obtained from an ad-hoc procedure that starts from the official NA series available at very detailed economic activities and compiled according to the new ESA 2010 (EU Regulation no. 549/2013) and aggregates the value of the variables for Nace Rev.2 sections, before calculating the compensation of employees, per employees. When comparing LCS and NA indicators it is important to keep in mind that the two sources use different methodologies to estimate the considered aggregates. The NA data, in particular, include regular and irregular workers of all enterprises, while LCS data include only regular workers of the enterprises with 10 or more employees.
The definitions of compensation of employees in LCS and NA (code D1 in both statistics) are quite similar. As a matter of fact it is not clear whether the tiny differences that can be spotted between the two regulations must be interpreted as a result of an intention of the legislator or whether they can be ascribable only to a different way of writing down the definitions.
The empirical comparison of LCS and NA data (table 8.5.1) shows quite pronounced differences. This is probably due to the differences in coverage as above stated. Being the labour cost increasing with enterprise size, LCS labour costs appears higher in almost all NACE sectors. For Accommodation and food services (sector I), for the Construction (section F), for Real estate activities (sector L), Arts sports and recreation (sector R) and Other service activities (S) the divergence in the annual growth rate of compensation of employees is mainly due to the different coverage, in fact, the number of LCS employees is much less than half of that of NA. Furthermore, Wholesale and retail trade (section G), Professional, scientific and technical activities (section M) the LCS coverage, in terms of number of employees, is just over half of that of NA. A further factor explaining the difference in favour of LCS is the fact that the NA statistics include also irregular employees which have labour costs much lower than regular employees.
As concern Public administration and defence, compulsory social-security (section O), the divergence is mainly due to the higher share of social contribution collected by NA than in LCS.
Table 8.5.1 - Compensation of employees per employee NA vs LCS. Year 2020
Each data release and report publication respect a clear and understandable form, supported by metadata and guidance. All information is available and accessible on an impartial basis. No results will be sent back to responding units included in the sample.
When directly required specific methodological and technical information are given, too.
9.1. Dissemination format - News release
A national release with the main results and indicators was published on 14th December 2022 at web link: https://www.istat.it/it/archivio/278774 (Italian version). An English version is scheduled by January 2023
Istat provides microdata files from this survey, free of charge, for study and research purposes or for statistical-scientific purposes, in compliance with the regulations in force. Istat makes them available within its Laboratory for the Analysis of ELEmentari Data (ADELE), offering the world of scientific research a tool for carrying out independent analyses on survey microdata, in compliance with the data protection regulations (https://www.istat.it/en/information-and-services/researchers/laboratory-for-elementary-data-analysis).
Access to the ADELE Laboratory is only allowed to researchers from Entities recognised as research institutions by Comstat or included in the list of research institutions recognised by Eurostat.
9.5. Dissemination format - other
No results will be sent back to responding units included in the sample.
9.6. Documentation on methodology
C. BALDI, M. A. CIARALLO, S. DE SANTIS, R. RENZI, G. SPERA
C. BALDI,M.A.CIARALLO,S.PACINI,S.DE SANTIS The converging pattern between Business statistics and Administrative data. Towards an ‘industrialized’ statistical production process (2014) European Conference in Official Statistics Q2014 Vienna 2-5 June 2014. http://www.q2014.at/fileadmin/user_upload/The_converging_pattern_def.doc
The national release includes a glossary illustrating the main items definitions. Moreover it is accompanied by a methodological note describing the main aspects of the survey process and methodology applied.
9.7. Quality management - documentation
C. BALDI, C. CASCIANO, M. A. CIARALLO, M. C. CONGIA, S. DE SANTIS, S. PACINI Designing the integration of register and survey data in earning statistics (2016) European Conference in Official Statistics Q2016. Madrid 31 May-3 June 2016.
Further development in exploting both administrative and fiscal sources, have been planned in order to improve the quality of the next LCS edition. The aim is to continue to improve the process of integration of all admin sources in order to reduce the respondent burden.
The LCS 2020 is based on the Council Regulation (EC) No 530/1999 concerning structural statistics on earnings and on labour costs and the Commission Regulation 1737/2005. It provides details on the level and structure of labour cost data, hours worked and hours paid.
The target population is composed by all the enterprises and institutions belonging to the Private and Public sectors with at least 10 employees in the NACE Rev. 2 sections B to S.
Since 2012 edition Italy has provided also data related to section O (even if the extension to this section is still considered optional).
Not Applicable
The variables provided are those required in the regulations according to the definitions stated there
The sampling unit is the Economic Unit that is the Enterprise for the private sector and the Institution for the public sector. The observation unit, the one used to build up the aggregate data, is the territorial unit defined as the portion of economic unit in a Nuts1 region within the Economic Unit
The population covered in the LCS as requested by Regulation refers to the Enterprises and Institutions belonging to the Private and Public sectors with at least 10 employees in the NACE Rev. 2 sections B to S including O. The frame list, derived from the Italian Business Register (ASIA) referred to 2020, is composed by about 187,313 enterprises representing 9,198,453 employees as regard private sector and 17,803 institutions with 3,382,124 employees as regard public sector.
Data are disseminated at national level and NUTS 1 level
Not Applicable
not provided
Not Applicable
At the end of the statistical process the RACLI register has also been used to reweight the sample. The calibration variables are the number of employees, the social security wage and the number of hours paid. This has allowed to calculate weights that produce estimates aligned with the final version of the register, while at the time of the sampling selection, only a provisional version of the RACLI register was available.
Since LCS 2012 edition, the use of statistical registers built upon administrative data has gradually increased. The statistical processes for the Private and Public sectors are quite different. For the Private sector, data from a direct statistical survey was combined in all significant phases of the survey production process, with register data: the Annual Register of Individual Labour Costs (RACLI) data and the Business Register (ASIA) data. As for the public sector, data from the Labour Register (LR), from the Register of Public Institutions and data from administrative source have been used. In what follows, brief explanations of both are reported.
Registers and administrative data
The Labour Register is a statistical register containing information on employment and labour input, wages, contributions and income. It is the heart of labour statistics and its development in recent years has greatly enhanced the labour statistics either due to the production of output directly or by constituting a coordination framework able to provide much greater coherence to the entire system for labour statistics.
The setting up of such a register in Italy is extremely demanding as it is based on a plurality of administrative sources (see tables 3.1.1 and 3.1.2). The backbone of the system are the Social Security Institute (INPS) data and among them the UniEmens declarations. Moreover, the tax declarations, especially those submitted by the economic units for their workers (the new CU declarations) will be introduced both to guarantee a better coverage in term of units (e.g. is needed to ensure the coverage of not dependent jobs under an income threshold) and additional variables (e.g. those related to taxation and net income).
For the production of LCS 2020 two main registers (which can be viewed as subsets of the whole LR) have been used: for the private sector RACLI (which was also used for the 2016 edition of LCS) and for the public sector LR-public.
Table 3.1.1. Main sources for RACLI register
Table 3.1.2. Main sources for LR-public register
The statistical process for the Private sector
The survey for the private sector is a mixed register-sample survey process.
In fact, thanks to the availability of the RACLI register, LCS 2020 in the wake of what has already been done for the LCS 2016 an 2012 edition, has been designed introducing several solutions to allow a mutual integration between survey and register. In this approach, the register data assists the survey in some phases of the process, and the survey’s results can be used to check the register data and provide details not available in the Register.
The design of the process, therefore, had to take into account the timing of the availability of the register. Following the scheduled availability of Social Security data, the RACLI register is available as a provisional version in the autumn of year t+1 and, as a final version, in the spring of year t+2. So the provisional version was used for sampling, for prefilling the variables of the questionnaire and for checks during the data collection phase, while the final version was used for the post collection editing and imputation, including the imputation of non-responses, for calibration of the survey weights to known totals and for validation of the data. Moreover, the final data are used to evaluate comparatively the variables available in the register and those collected through the survey particularly to evaluate definitional issues.
This approach was guided, since LCS 2012 edition, by two main principles: the reduction in response burden: both the sample and the questionnaire were designed to obtain this objective, and the increase in the data quality, as it will be seen in the following paragraphs.
The frame list, derived from the Italian Business Register (ASIA) referred to 2020, is composed by 187,313 enterprises representing 9,198,453 employees. The final sample is composed by 24,521 enterprises.
The sampled enterprises had to provide data for the whole unit, through a web based questionnaire (CAWI) with some built in checks (first level checks). In a subsequent step the data are divided for each enterprise in the areas (NUTS1) in which the employees were localized with the help of information contained in the RACLI register. Thus the sampling unit is the enterprise and the observation unit (analysis unit) is the portion of enterprise comprised in one nuts1 area.
The statistical process for the Public sector
The statistical process of the public sector is entirely Register based. It is founded on two statistical registers, the Labour Register (LR) and the Register of Public Institutions and an administrative source, the Annual Account of the Ministry of Economy and Finance.
The frame list is derived from the institutions of the Register of Public institutions and the Labour Register. The final list is composed by 17,803 institutions with 3,382,124 employees.
Data sources
The statistical unit of the Labour Register is the job position, that is, for the employees, the employment relationship between an economic unit (the employer) and an individual (the worker) also identified by an activation date.
The LR for the public sector is fed by 5 main administrative sources: 1) the individual social contribution declarations that every month public institutions transmit to INPS through the PosPa List section of the Uniemens (ex-Inpdap source); 2) the individual monthly payslips compiled by the NOIPA system of the Ministry of Economy and Finance (MEF) for the administrations that have joined the system (IGOP source); the contribution declarations that the economic units of the public sector transmit to the INPS through the section Lista Poslav of the Uniemens divided into those produced: 3) by the MEF Data Processing Centre, as a withholding agent, for employees, mainly temporary, of some ministries (source CedInps) and 4) from all other withholding agents of the public perimeter that for administrative reasons use the section Poslav List as private sector enterprises (source Private); 5) the yearly tax declarations (source CU).
These sources, after data treatments aimed at eliminating duplications and harmonizing them, are integrated into a single database, with monthly information for each job position. In this phase an important role is played by the information taken from the Matrix of links between administrative units and institutional units produced within the operations for the Register of Public Institutions.
At this level the Register contains information on the characteristics of the job position (national collective agreement –NCA-, job title, type of working time, percentage of part-time, type of contract), on the labour input, measured as the average number of monthly positions, and the number of hours paid net of overtime. The number of overtime hours is estimated a) for the job positions covered by the IGOP source, using the wages for overtime hours, contained in this source, and the average hourly overtime rates from the collective agreements and the Annual Account and b) for the rest of the population of job positions with a massive imputation method that uses information from the Labour Force Survey.
The Annual Account is a takes-all survey carried out by the Ministry of Economics and Finance - General Accounting (RGS) to measure the personnel costs of public institutions. The data of the Annual Accounts, have been suitably studied, analyzed, and reclassified to produce data that fit the definitions of Labour Cost Survey regulation (Commission Implementing Regulation 1737/2005). Finally, for a very limited number of units the data were collected through the questionnaire built for the private sector. These are units that only recently passed from the population belonging to the private sector (as defined by the Business Register Asia) to the one belonging to the public sector and in particular in the list S13. These units are not yet covered by the Annual Account and are broadly similar, in many respects, to private sector units.
Data Processing
The data processing for the public sector consists in the construction of a takes-all database on public sector units with the variables required by the LCS regulation. The processing steps can be summarized as follows. First, LR data on labour inputs and paid hours, broken down by type of working time, and wages are aggregated by legal unit, NCA code, job title code. The second phase is to group from the Annual Account data on hours of absence, wages, contributions and other labour costs (according to the LCS classification) by institutional unit, NCA code, job title code. In the third stage, the information of this second database is used to impute the LCS missing variables in the first database, at legal unit, NCA code, job title code. In the fourth phase, the data are aggregated at the legal unit level and the classification variables, such as the economic activity and the territorial location, derived from the Register of Public Institutions and the Matrix of links between administrative units and institutional units, are added to the data. At this stage, in relation to the Ministry of Education, University and Research (MIUR), Educational and Training Institutions are classified in Section P of the NACE (Education), while the rest of the Ministry is classified in Section O (Public Administration and Defence; Compulsory Social Insurance). In the last step, the data is subject to editing and imputation procedures that adopt the same techniques and software used for private sector data.
Not Applicable
The data appeared for the first time on Eurostat database on December 1st 2022. Thus the length of time between the end of the reference year (2020) and the first publication of data is of 23 months.
The LCS 2020 complies with the standard set up on the Council Regulation (EC) No 530/1999 concerning structural statistics on earnings and on labour costs and with the definitions of variables adopted in the Commission Regulation 1737/2005.
The LCS 2020 is broadly comparable with the previous edition of LCS (2016) for what concerns the main aggregates. The main, methodological and technical aspects have not been changed, nevertheless some indicators must be compared with a particular caution considering the events characterizing labour market in the pandemic year. Furthermore, some choices of the E&I and estimation have been made to allow a better mutual integration between survey data and administrative . For these reasons some indicators may have problems of comparability (like hourly indicators, hours per capita.) due to differences in measuring variables between register and survey (for example for the variables “hours paid” and “hours worked”). Another area in which there might be problems of comparability is the public sector: as for the LCS 2016 edition the entire process is based on administrative data, but in this edition the sources used are partially different from the previous edition. Moreover some parameters used for the estimation of not available variables have been revised compared to the previous edition. Furthermore as regard sector P, some methodological changes caused the increasing of the estimation of hours worked. In the LCS 2020 edition, in fact, the process improves the estimation hours worked of Education sector by adding the hours of not frontal teaching to the contractual hours, and using a new method of estimating overtime hours.