|
  
| En la sección «Colaboraciones»
se recogen opiniones y propuestas firmadas por lectores o por miembros
de la Redacción cuando intervienen a título personal. La
responsabilidad de los cabos sueltos firmados y de las colaboraciones
incumbe a sus autores. PUNTOYCOMA |
COLABORACIONES
Aplicaciones de la Lingüística de Corpus a la práctica de la Traducción
Complemento de la Traducción Asistida por Ordenador
En el número 2.2002 de la revista Terminologie & Traduction, se halla publicada la versión íntegra de este artículo de Pilar Sánchez-Gijón.
Existe toda una tipología de los córpora en función del número de lenguas representadas (monolingüe, bilingüe, multilingüe), la relación existente entre los diferentes textos (originales, originales y traducciones), u otros criterios. No obstante, pensando en las aplicaciones de la Lingüística de Corpus en la práctica de la Traducción, podríamos dividir los diferentes tipos de córpora ya establecidos en dos categorías: por un lado los que permiten estudiar traducciones, y por otro los que ofrecen recursos para la traducción.
Sin embargo, como veremos, el traductor no siempre encuentra la información que necesita en los córpora existentes, por lo que puede acabar compilando su propio corpus para fines específicos. En este artículo se muestran posibles métodos de explotación de córpora ad hoc como recurso para la traducción especializada utilizando herramientas de gestión e interrogación de córpora.
1. Los córpora existentes
Tal como se mencionaba en la introducción, desde el punto de vista de la Traducción los córpora se pueden dividir en dos grandes categorías: las colecciones de textos que permiten estudiar las traducciones y las que permiten extraer recursos para la traducción. En la primera se encontrarían los córpora que permiten estudiar traducciones, como los denominados córpora paralelos. Este tipo de córpora incluye textos originales en una lengua y su traducción a una o más lenguas, de modo que original y traducción se puedan alinear. Desde este perspectiva, una memoria de traducción podría constituir por ella misma un corpus paralelo. También pertenecen a este grupo aquellos córpora monolingües que incluyen textos originales y traducidos. Este segundo tipo de córpora es menos habitual que el primero.
En la segunda categoría, la constituida por los córpora que ofrecen recursos para la traducción, se encuentran los córpora de grandes dimensiones, los de referencia, que incluyen el máximo número de textos posibles de una lengua, pertenecientes a todo tipo de ámbitos. Es el caso, por ejemplo, del Corpus de Referencia del Español Actual (CREA) de la Real Academia Española1, o de The Bank of English de Cobuild y la Universidad de Birmingham. También figuran en esta categoría los denominados córpora comparables, aquellos formados por textos originales similares en dos o más lenguas o variantes de una lengua; generalmente se trata de colecciones por géneros en diferentes lenguas. Estos dos tipos de córpora ofrecen información lingüística de tipo pragmático que puede resultar de gran ayuda para el traductor, tanto en la lengua de partida como en la de llegada.
Si bien esta segunda categoría constituye una fuente de recursos lingüísticos inestimable para el traductor, aunque a menudo infrautilizada, en ocasiones no ofrece respuesta a consultas sobre usos lingüísticos en ámbitos de conocimiento muy especializados o de gran actualidad. Al realizar una traducción, el traductor suele solucionar problemas de este tipo recurriendo a lo que la Teoría de la Traducción denomina textos paralelos: textos originales en la lengua de partida o en la de llegada sobre el mismo tema y cuya función es similar o equivalente a la de la traducción2. Actualmente, los traductores, sobre todo ante traducciones especializadas, suelen documentarse recurriendo a la gran biblioteca virtual, Internet, ya que por lo general es el medio en el que encontrarán la información más actual y el que se la puede ofrecer de forma prácticamente inmediata. Al localizar un texto paralelo, el traductor lo lee, normalmente en diagonal, en busca de la información que necesita, que puede ser un término, una colocación verbal o cualquier otro elemento lingüístico. En esta fase de análisis de los textos paralelos, el traductor puede sacar partido de las herramientas y de la metodología que le proporciona la Lingüística de Corpus: puede generar un corpus con los textos paralelos que ha recogido y explotarlos mediante programas diseñados para la gestión e interrogación de córpora.
Este tipo de córpora, recopilados con un objetivo concreto, se denomina córpora ad hoc (Aston, 1999)3. Se compilan únicamente para ser analizados en función de un solo objetivo: en este caso ser utilizado como texto paralelo en la lengua de llegada y obtener de él información de tipo tanto lingüístico como cognitivo que permita al traductor especializado conseguir los conocimientos necesarios para realizar una traducción en un dominio determinado. Para ilustrar la extracción de información de un corpus de estas características utilizaremos una colección de textos compuesta por textos dedicados al ámbito de la observación de un fenómeno astronómico denominado Leónidas en lengua española, obtenidos en Internet mediante una búsqueda realizada a partir de las palabras clave Leónidas y Astronomía. Está formado por 121 textos, que son 121 páginas de Internet provenientes de 27 documentos hipertextuales diferentes4. Este conjunto de textos suma un total de 162 356 formas5, se trata por lo tanto de un corpus pequeño.
2. El análisis del corpus ad hoc
Lo que el traductor especializado busca en los textos paralelos, por un lado, son datos lingüísticos como unidades terminológicas y expresiones o usos habituales del lenguaje de especialidad y, por otro lado, aumentar su capacidad cognitiva, sus conocimientos sobre ese dominio, para llegar a comprender el original y poder redactar su traducción con propiedad. Lo cierto es que, habitualmente, al adquirir la información lingüística sobre el lenguaje de especialidad también adquirimos el conocimiento que dicha información vehicula, por lo que puede resultar difícil disociar un tipo de información del otro.
2.1 El análisis superficial
El objetivo de este primer análisis es doble: en primer lugar, asegurarnos de la adecuación del corpus al tema de la traducción que se ha de llevar a cabo, y en segundo lugar, familiarizarnos con las características del lenguaje de especialidad del dominio en cuestión. Para realizar un primer acercamiento al corpus que hemos recogido podemos intentar averiguar su tema principal. Normalmente, el título de cada uno de los textos resume el tema que desarrollan. También suelen utilizarse fórmulas lingüísticas estereotipadas en mayor o menor grado que permiten que el autor presente al lector los términos principales que se desarrollan en el texto, como conocido como o llamado. Partiendo, por ejemplo, de la primera de estas opciones, realizamos una búsqueda de concordancias de la expresión conocid* como6. El resultado recoge 16 concordancias de las que 10 presentan el término Leónidas. Algo similar sucede, aunque en menor medida, con las fórmulas denominado y llamado.
El traductor especializado recurriría al corpus para resolver dudas lingüísticas puntuales, como por ejemplo la composición de colocaciones. Para ilustrar el modo de identificar colocaciones, expresiones fraseológicas o términos sintagmáticos, entre otros elementos lingüísticos, analizaremos el contexto del término Leónidas. A partir de las concordancias del término Leónidas estudiaremos en qué contextos aparece. Podemos iniciar el estudio del contexto de un término observando las palabras que más a menudo la acompañan: sus cosituados (collocates)7. Tomando como contexto desde la quinta palabra a la izquierda de Leónidas hasta la quinta palabra a su derecha, observamos que las palabras de mayor frecuencia de aparición, además de artículos y preposiciones, son meteoro, lluvia, tormenta, luna, observar, observación... Al concentrarnos en los segmentos que incluyen Leónidas y lluvia o tormenta obtenemos los siguientes resultados: lluvia aparece acompañando directamente a Leónidas (lluvia de Leónidas o lluvia de las Leónidas) en 19 ocasiones, mientras que la frecuencia de tormenta junto con Leónidas (tormenta de Leónidas o tormenta de las Leónidas) resulta mucho más alta. Al observar con mayor atención los contextos de lluvia observaremos que también sobresale el uso de «lluvia de meteoros», «lluvia de estrellas» y «lluvia de estrellas fugaces»; por el contrario, tormenta parece utilizarse únicamente con Leónidas, ya sea directamente con Leónidas (tormenta de Leónidas) o intercalando meteoros (tormenta de meteoros Leónidas).
La utilidad del análisis superficial de un corpus ad hoc recopilado como recurso para la traducción cobra sentido únicamente si se realiza para resolver problemas concretos de traducción. No es recomendable realizar un análisis superficial exhaustivo de un corpus de este tipo, ya que el traductor podría invertir muchos esfuerzos en extraer información lingüística que ya pudiera poseer con anterioridad o que le pudieran ofrecer directamente otro tipo de fuentes.
2.2 El análisis cognitivo o conceptual
En el momento de comprender la dimensión conceptual de algunos términos que el traductor no conoce en profundidad, o de decidir cómo representar un concepto determinado en el texto de llegada, el traductor necesita llevar a cabo una investigación puntual a partir de diferentes obras de referencia o textuales. La función del análisis cognitivo o conceptual del corpus ad hoc es la de extraer tanta información conceptual relacionada con un término determinado como sea posible partiendo de la forma, de la superficie del texto. Consiste en sistematizar el modo de realizar las investigaciones conceptuales puntuales a las que hemos hecho referencia en el párrafo anterior.
Este análisis se realiza fundamentalmente partiendo de fórmulas discursivas habituales que vehiculan o implican relaciones conceptuales o que explicitan propiedades concretas de un concepto determinado. Para ilustrar este análisis, intentaremos reproducir la dimensión cognitiva del término Leónidas en función de la información que proporcionan los textos recogidos en el corpus. Intentaremos obtener una definición del término Leónidas. Para ello nos basaremos en expresiones verbales que suelen hacer de puente entre la denominación de un término y la definición que el autor propone. En concreto nos basaremos en las formas del presente de indicativo del verbo ser. Lo que buscaremos serán contexto de Leónidas en los que aparezca inmediatamente a su derecha alguna forma del presente de indicativo del verbo ser. La primera búsqueda la realizamos a partir de «es»; a continuación extraemos concordancias a partir de «son». En total hemos localizado catorce concordancias de «Leónidas + es» o «Leónidas + son». Al ampliar estos contextos hasta obtener la oración completa, tenemos acceso a la información que resumimos en la siguiente figura:
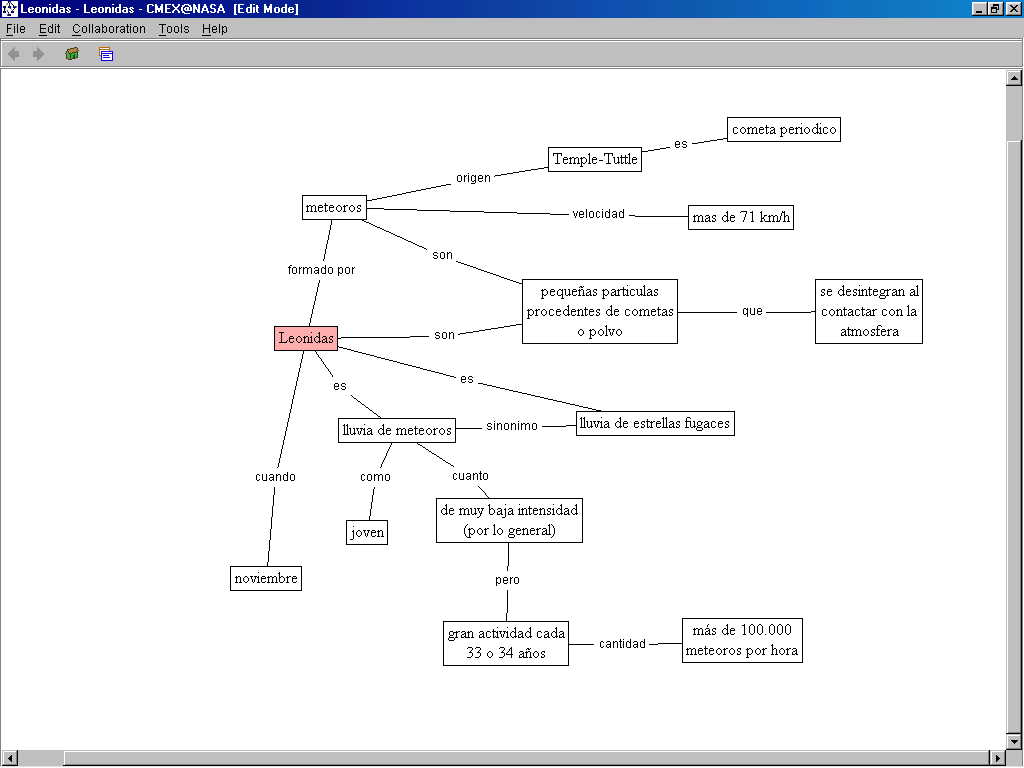
Figura 1: Esquema definicional del término Leónidas8
Las dos búsquedas de concordancias nos han facilitado la localización de la información que necesitábamos, nos han permitido leer directamente los segmentos procedentes de cualquier texto de nuestro corpus. La búsqueda de definiciones implícitas en el texto no solamente se puede llevar a cabo a partir del verbo ser, también se utilizan habitualmente otros verbos con la misma función, como por ejemplo denominar, conocer como, llamarse o llamar (llamado), entre otros.
Para poder generar el mapa conceptual de Leónidas que relacione este concepto con el resto de nociones del dominio, se debería llevar a cabo fundamentalmente dos tipos de extracciones de concordancias. Por un lado, si la información que se desea obtener es la relación existente entre dos conceptos, extraeríamos concordancias en las que aparecieran ambos términos y observaríamos cómo se vinculan en contexto. Por otro lado, si lo que se desea conocer es con qué conceptos guarda el término de partida, en nuestro caso Leónidas, una relación conceptual determinada, como por ejemplo cualquiera de las relaciones recogidas en BACUS (lógicas, analógicas, ontológicas, infralógicas o argumentales) (Aguilar-Amat i Castillo, 2002), los criterios de partida de la búsqueda serán el término y una expresión que explicita la relación conceptual que nos interese en ese momento. Expresado en términos matemáticos, la interrogación del corpus con estos fines se basa en una ecuación en la que intervienen dos factores conocidos y una incógnita.
Conclusiones
Partiendo de las características formales del discurso especializado, el uso de herramientas digitales diseñadas para la gestión de corpus sobre córpora recogidos ad hoc como recursos para la Traducción permite identificar de manera estadística unidades terminológicas, fraseologías o expresiones habituales en el discurso especializado de un dominio determinado, así como localizar en los textos aquellos segmentos que contienen información conceptual sobre aspectos que puedan resultar relevantes. Una vez obtenida la información en forma de concordancias, la tarea del traductor consiste en saber leerla e interpretarla, hacerla encajar con datos anteriores, continuar tejiendo el manto cognitivo del dominio en el que trabaja.
Bibliografía
(Abaitua, 2000) Abaitua, Joseba: Tratamiento de corpora bilingües, trabajo presentado en el Seminario «La ingeniería lingüística en la sociedad de la información», Soria, 17-21 de julio de 2000. Fundación Duques de Soria. Versión consultada: <http://www.serv-inf.deusto.es/abaitua/konzeptu/ta/soria00.htm> [Consulta: septiembre de 2001]
(Aguilar-Amat i Castillo, 2002) Aguilar-Amat i Castillo, Anna: «Traducción, computación, utopía», en
PUNTOYCOMA. Boletín de las Unidades Españolas de Traducción de la Comisión Europea,
nº 73 (enero/febrero), 2002.
(Cabré, Codina, 2001) Cabré Castellví, M. T. y Lluís Codina: «Terminologia i documentació: necessitats recíproques i camps d'aplicació», en Cabré Castellví, M. T.; Codina, Lluís i Estopà, Rosa (eds.): Terminologia i Documentació. I Jornada de Terminologia i Documentació (24 de maig de 2000). Barcelona: Institut Universitari de Lingüística Aplicada, UPF, 2001, pp. 13-30.
(Corpas, 2000) Corpas, Gloria 2000: «Compilación de un corpus ad hoc para la enseñanza de la traducción inversa especializada», trabajo presentado en el Seminario de Documentación, Terminología y Traducción: Técnicas documentales aplicadas a la traducción científica. Soria, 25-29 de septiembre de 2000.
(Gómez, 1999) Gómez, Remigio: «Internet en la traducción», en
PUNTOYCOMA, Boletín de las Unidades Españolas de Traducción de la Comisión Europea,
nº 57 (mayo/junio), 1999 [Consulta: 25 de julio de 2001].
(Pearson, 1998) Pearson, J.: Terms in Context, Studies in Corpus Linguistics, 1. Amsterdam/Philadelphia: John Benjamins Publishing, 1998.
(Sánchez-Gijón, 2001) Sánchez-Gijón, Pilar: «Anàlisi de textos catalans en línia. Repercussions en la traducció especialitzada» trabajo presentado en el V Congreso Internacional de Traducción. Interculturalidad y Traducción: las lenguas menos traducidas. Dep. de Traducció i Interpretació de la UAB, Bellaterra, 29-31 de octubre de 2001.
(Sinclair, 1996) Sinclair, John: «Preliminary recomendations on corpus
typology» a Eagles Guidelines, versión de mayo de 1996. Expert Advisory Group on Language Engineering
Standards [Consulta: mayo de 2001].
Pilar Sánchez-Gijón
Prof. Asociada del Departament de Traducció i d'Interpretació
Universitat Autònoma de Barcelona
pilar.sanchez.gijon@uab.es
|
1. | El CREA se puede consultar en línea. | | 2. | Hemos creído necesario diferenciar en este punto entre lo que es un texto o corpus paralelo para la Lingüística de Corpus (original con su traducción a otra lengua) de lo que representa para la Teoría de la Traducción (originales de temática idéntica y función equivalente). |
| 3. | Según Jennifer Pearson, se trataría también de un «special purpose corpus, a corpus whose composition is determined by the precise purpose for which it is to be used» (Pearson, 1998: 48). |
| 4. | A efectos terminológicos, entendemos por documento hipertextual un documento publicado en Internet, conocido normalmente como un sitio web, que está formado por diferentes nodos, las páginas, que formalmente son archivos diferentes. |
| 5. | Adoptamos la propuesta de la Real Academia Española de traducir el término inglés token por forma: las formas son el conjunto de palabras que aparecen en un corpus, teniendo en cuenta repeticiones, diferentes formas verbales, etc. |
| 6. | Al utilizar el comodín nos aseguramos de que el programa recupere conocido en todas sus posibles formas (conocido, conocida, conocidos, conocidas). |
| 7. | Denominación sugerida por Diego Echauz-Brigaldi, de la Dirección General de Traducción de la Comisión Europea, en la conferencia que dio lugar al presente articulo, que tuvo lugar en Bruselas el 18 de enero de 2002. |
| 8. | Este esquema se ha realizado con la ayuda del programa denominado Concept Map Tools, versión 2.9.1, desarrollado por el
Institute of Human and Machine Cognition de la University of West Florida. |
|