Archive:Inflation – methodology of the euro area flash estimate
- Data from October 2016 to October 2017 - extracted on 16 November 2017. Next planned article update: 18 December 2017.
Changes in the price of consumer goods and services are usually referred to as the inflation rate. Inflation is an increase in the general price level of goods and services. When there is inflation in an economy, the value of money decreases because a given amount will buy fewer goods and services than before. This article analyses the accuracy of the euro area inflation flash estimates, usually released at the end of the reference month and describes the methodology used in their production.

Accuracy of the flash estimates

The aim of the inflation flash estimates is to predict as accurately as possible the actual inflation rate released later. Since accuracy is the degree of closeness of measurement of a quantity to that quantity's actual (true) value, the flash estimate is considered to be accurate if its value, rounded to one decimal place, is the same as the HICP annual rate, rounded to one decimal, published two weeks later. Table 1 compares the flash estimates and the HICP annual rates for the same reference month. The table represents data at the time of first publication, unrevised. Over the last 12 months, the maximum difference between the all-items flash estimate and the HICP annual rate was 0.
The mean absolute deviation provides another way to measure accuracy. It is the average of the absolute differences between the flash estimate and the HICP annual rate over time. Figure 1 shows the mean absolute deviation over the last 12 months.
The unprocessed food component has recorded the highest mean absolute deviation over the last 12 months.
A third way to evaluate the flash estimates' accuracy is to look at how they predict the direction of inflation. The flash estimate correctly predicts the direction of inflation if the difference between the flash estimate and the previous month inflation has the same sign as the difference between the actual inflation and the previous month inflation. For example, if the flash estimate is pointing to an increase on inflation and that increase is confirmed two weeks later, then the direction of inflation was accurately predicted.
There are three possible outcomes for the direction comparison:
- The flash estimate correctly predicts the direction of inflation if the predicted increase / decrease / no change in inflation is confirmed (denoted by
 );
); - The flash estimate wrongly predicts the direction of inflation, e.g., it predicts an increase when there is a decrease (denoted by
 );
); - The flash estimate points to an increase / decrease but the final figure remains unchanged; or the flash estimate predicts no change in inflation but the final figure points to an increase / decrease (denoted by
 )
)
Over the last 12 months the flash estimate accurately predicted the inflation's direction in 118 out of 120 estimates. The following table represents data at the time of first publication, unrevised.

The first flash estimate breakdown into 'food', 'non-energy industrial goods', 'energy' and 'services' was published in September 2012. Prior to that, flash estimate figures for these four main components were computed to test the accuracy of the algorithm in predicting their respective inflation rates, but only the all-items estimate was published at the end of each reference month. The estimates for ‘all-items excluding energy’ and ‘all-items excluding food and energy’ were added in April 2013. The estimates for 'processed food', 'unprocessed food' and 'all-items excluding energy and unprocessed food' were added in September 2014.
Computation of flash estimates
The flash estimate procedure combines early HICP information from the euro area countries with a one-step ahead forecast for countries that were not able to provide preliminary information. Forecasts are based on statistical models which use timely energy price data from the Weekly Oil Bulletin, HICP back series and the preliminary data for the available countries. The model estimates national HICPs and their main components (if not provided by a Member State) and aggregates them to the euro area level, together with the available flash estimates provided by the countries, to produce the flash estimates for the reference month. The euro area members that currently provide preliminary data for the flash estimates are: Belgium, Germany, Ireland, Greece, Spain, France, Italy, Cyprus, Lithuania, Luxembourg, Netherlands, Austria, Portugal, Slovenia, and Finland. For the all-items estimate, the maximum country coverage is 99% of the euro area weight.
There are four main steps that take place sequentially:
- Processing energy prices data;
- Processing available data;
- Forecasting and calibration;
- Euro area aggregation
STEP 1: Processing energy prices data
To improve the forecasting power of the model, the HICP data are combined with timely price data on fuels and heat energy. The information is received from The European Commission Diretorate-General for Energy Weekly Oil Bulletin, where weekly prices of diesel, petrol and heating oil are published. At the time of the flash release, the energy price data of the last week of the month are normally missing; an automatic forecast for the missing week is made for each euro area country, and the monthly averages calculated from these weekly price data are used in the flash estimate procedure.
STEP 2: Processing available data
Countries are separated into two groups: group 'A' countries, which have provided preliminary data for the current month, and group 'N' countries, which have not. For each group, the available data for HICP and energy prices are aggregated into a single index; i.e., for the all-items aggregate, one index is created for group 'A' and one for group 'N'; for 'food', one index is created for group 'A' and another for group 'N', and so on. The HICP index for group 'A' has one extra observation (i.e. the preliminary data for the month in question) compared to the index series for group 'N'.
STEP 3: Forecasting and calibration
For each aggregate, a one-step ahead forecast for the group ‘N’ HICP index is performed using a SARIMA model with the group ‘A’ HICP index computed in Step 2 and the energy price data processed in Step 1 as possible regressors. For each aggregate, the best-performing model specifications are found and applied through an automatic model selection procedure, based on historical data, the relationship between the two sets of indices, and energy prices. The forecasted indices are calibrated to ensure that they form a consistent set.
STEP 4: Euro area aggregation
The one-step ahead forecast indices obtained in step 4 are aggregated with the aggregate of 'A' countries preliminary data, producing the euro area HICP flash estimate for each sub-component of the flash estimate.

Models used
Prior to any model fitting, the first differences of the logs are taken:
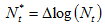 where
where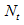 is the aggregated index of the set of countries that have not provided any preliminary data. This will be the dependent variable to be forecasted;
is the aggregated index of the set of countries that have not provided any preliminary data. This will be the dependent variable to be forecasted;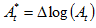 where
where 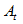 is the aggregated index of the set of countries that have provided preliminary data;
is the aggregated index of the set of countries that have provided preliminary data;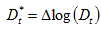 where
where 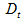 is the weighted average of 'diesel' prices of the set of countries that have not provided preliminary data;
is the weighted average of 'diesel' prices of the set of countries that have not provided preliminary data;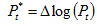 where
where 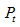 is the weighted average of 'petrol' prices of the set of countries that have not provided preliminary data;
is the weighted average of 'petrol' prices of the set of countries that have not provided preliminary data;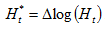 where
where 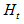 is the weighted average of 'heat' prices of the set of countries that have not provided preliminary data.
is the weighted average of 'heat' prices of the set of countries that have not provided preliminary data.
For each aggregate, a model with ![]() ,
, ![]() and
and ![]() as possible regressors is used to obtain an estimate for the current month's
as possible regressors is used to obtain an estimate for the current month's ![]() index,
index, ![]() . Depending on the special aggregate, some regressors might not be significantly correlated with the dependent variable, so they are not likely to be used in the forecasting model.
. Depending on the special aggregate, some regressors might not be significantly correlated with the dependent variable, so they are not likely to be used in the forecasting model.
The model used to estimate missing country data is a regression model with SARIMA errors, given by:

The parameters for the SARIMA and the regressors to be used are determined on a case by case basis so as to maximise accuracy.
The forecast ![]() is given by:
is given by:
 where
where ![]() is a forecast from the SARIMA model shown above. The forecast for the index is therefore given by
is a forecast from the SARIMA model shown above. The forecast for the index is therefore given by ![]() .
.
Direct and indirect forecasts
The estimation procedure described above is used to obtain a direct forecast of ![]() for the ‘all-items’, ‘food’, 'non-energy industrial goods', 'energy', 'services' and ‘all-items excluding food and energy’ indices. To improve the accuracy of the final ‘energy’ estimate, its two subcomponents, ‘ELC_GAS’ (the result of the aggregation of electricity, gas, solid fuels and heat energy) and ‘fuels’ (the result of the aggregation of liquid fuels and fuels and lubricants for personal transport equipment) are also forecasted directly using the same method. The calibration phase (see next section) ensures that these direct forecasts satisfy the consistency constraints (i.e. the aggregation of the 'food', 'non-energy industrial goods', 'energy' and 'services' indices must be equal to the all-items index, the aggregation of the ‘ELC_GAS’ and ‘fuels’ indices must be equal to the ‘energy’ index, etc.).
for the ‘all-items’, ‘food’, 'non-energy industrial goods', 'energy', 'services' and ‘all-items excluding food and energy’ indices. To improve the accuracy of the final ‘energy’ estimate, its two subcomponents, ‘ELC_GAS’ (the result of the aggregation of electricity, gas, solid fuels and heat energy) and ‘fuels’ (the result of the aggregation of liquid fuels and fuels and lubricants for personal transport equipment) are also forecasted directly using the same method. The calibration phase (see next section) ensures that these direct forecasts satisfy the consistency constraints (i.e. the aggregation of the 'food', 'non-energy industrial goods', 'energy' and 'services' indices must be equal to the all-items index, the aggregation of the ‘ELC_GAS’ and ‘fuels’ indices must be equal to the ‘energy’ index, etc.).
Finally, the ![]() index for ‘all-items excluding energy’ is obtained by aggregating the calibrated indices for ‘food’, 'non-energy industrial goods' and ‘services’. Using this indirect approach for ‘all-items except energy’ has proved to improve the overall accuracy of the set of estimates.
index for ‘all-items excluding energy’ is obtained by aggregating the calibrated indices for ‘food’, 'non-energy industrial goods' and ‘services’. Using this indirect approach for ‘all-items except energy’ has proved to improve the overall accuracy of the set of estimates.
Calibrating the special aggregates
The calibration procedure for the 1-step ahead forecasts of the ‘N’-group countries is based on a Stone-style balancing procedure and is anchored to maximum likelihood estimation theory. The mean square deviation (MSD) of each 1-step ahead forecast performed is estimated. The forecasted indices are then allowed to vary to satisfy the consistency constraints. The amount by which each forecasted index varies is proportional to its MSD. This means that usually accurate forecasted indices (low MSD) will vary little, while indices for which predictions are harder (high MSD) will undergo a more substantial adjustment to achieve consistency.
See also
Further Eurostat information
Data visualisation
Database
- Harmonised indices of consumer prices (HICP), see a predefined selection under these links:
- HICP (2015 = 100) - monthly data (annual rate of change) (prc_hicp_manr)
- HICP (2015 = 100) - monthly data (monthly rate of change) (prc_hicp_mmor)
Dedicated section
Methodology / Metadata
- Harmonised indices of consumer prices (HICP) (ESMS metadata file — prc_hicp_esms)
- COICOP/HICP classification - COICOP/HICP classification
External links
- European Central Bank - Survey of Professional Forecasters
- European Commission - Directorate-General for Economy and Finance - Economic Forecasts