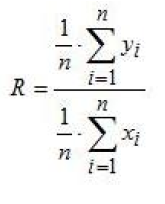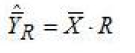Reference metadata describe statistical concepts and methodologies used for the collection and generation of data. They provide information on data quality and, since they are strongly content-oriented, assist users in interpreting the data. Reference metadata, unlike structural metadata, can be decoupled from the data.
Structural business statistics (SBS) describes the structure, conduct and performance of economic activities, down to the most detailed activity level (several hundred economic sectors). SBS covers all activities of the business economy with the exception of agricultural activities, public administration and (largely) non-market services such as education and health. Main characteristics (variables) of the SBS data category:
"Business demographic" variables (e.g. Number of active enterprises)
"Output related" variables (e.g. Net turnover, Value added)
"Input related" variables: labour input (e.g. Number of employees and self-employed persons, Hours worked by employees); goods and services input (e.g. Purchases of goods and services); capital input (e.g. Gross investments)
Business services statistics (BS) collection contains harmonised statistics on business services. From 2008 onwards BS become part of the regular mandatory annual data collection of SBS. The BS’s data requirement includes variable “Turnover” broken down by products and by type of residence of client.
The annual regional statistics collection includes three characteristics due by NUTS-2 country region and detailed on NACE Rev. 2 division level (2-digits).
3.2. Classification system
Statistical Classification of Economic Activities in the European Community (NACE): NACE Rev.2 is used from 2008 onwards. Key data were double reported in NACE Rev.1.1 and NACE Rev.2 only for 2008. From 2002 to 2007 NACE Rev. 1.1 was used and until 2001 NACE Rev.1
Starting reference year 2021 onwards SBS cover the economic activities of market producers within the NACE Rev. 2 Sections B to N, P to R and Divisions S95 and S96. Until 2007 the SBS coverage was limited to Sections C to K of NACE Rev.1.1 and from the reference year 2008 to 2020 data was available for Sections B to N and Division S95 of NACE Rev.2. From 2013, as the first reference year, to 2020 information is published on NACE codes K6411, K6419 and K65 and its breakdown.
From 2008 reference year data collection Business Services covers NACE Rev 2 codes: J62, N78, J582, J631, M731, M691, M692, M702, M712, M732, M7111, and M7112.
3.4. Statistical concepts and definitions
SBS constitutes an important and integrated part of the new European Business Statistics Regulation N° 2152/2019
Surveying all legal units belonging to a complex enterprise
No
Surveying all legal units within the scope of SBS belonging to a complex enterprise
Yes
Surveying only representative units belonging to the complex enterprise
No
Other criteria used, please specify
truncated enterprise group
Comment
-
3.5.2. Consolidation
Consolidation method
Consolidation carried out by the NSI
Yes
Consolidation carried out by responding enterprise/legal unit(s)
No
Other methods, please specify
-
Comment
-
3.6. Statistical population
Only active market units are included.
Active units encompass the following units:
units with a non-zero value of turnover, non-zero value of operating costs or non-zero employees;
units which are active according to the SBS survey and not properly recorded in the administrative sources (e.g. VAT exempt units without employment and not having filed their detailed financial statements yet);
The market status of a unit is defined in terms of the national accounts institutional sectors. Sectors 12.7, 13 and 15 are excluded from the target population. The following units are specifically excluded:
temporary partnerships;
private persons producing energy using photovoltaic installation;
artificial subsidiaries and other special purpose entities dealing almost exclusively with group affiliates.
There are no exclusions in terms of NACE. However, branch H.50 (water transport) is only available as a branch estimate and not as micro-data. Consequently, the size class dimension is not reliable for this activity branch.
3.7. Reference area
Luxembourg economic territory.
3.8. Coverage - Time
The available time series covers the reference years starting from 1995 to 2022.
The length of comparable series is as follows:
1995 - 2002 (KAU concept);
2003 - 2008 (enterprise concept NACE Rev.1.1);
2005 - 2023 (enterprise concept NACE Rev.2).
Reference years 2005 to 2007 were subject to voluntary back-casting in NACE Rev.2.
Reference year 2008 marks the first year under the SBS Recast Regulation, until 2020.
As of reference year 2019, Luxembourg introduced a rolling revision policy for SBS. This policy consists in revising the previous SBS reference year rather than revising several SBS reference years at the same time.
As of reference year 2021, the SBS have been extended to NACE sections P, Q, R and K as well as NACE division S96, in conformity with the EBS regulation. Another feature of EBS is the stricter alignment with business demography.
For information on any breaks in the time series, please refer to section 15.2.
3.9. Base period
Not applicable.
Number of enterprises and number of local units are expressed in units.
Monetary data are expressed in millions of €.
Employment variables are expressed in units.
Per head values are expressed in thousands of € per head.
Ratios are expressed in percentages.
2023
The reference year corresponds with the calendar year.
For each company with a different financial year than the calendar year, we take a decision regarding the SBS reference period. Normally, this decision is taken in such a way that at least 6 months of the financial year for a given company are included in the corresponding SBS reference period. Once that decision is taken, it is maintained every subsequent year for comparability reasons.
6.1. Institutional Mandate - legal acts and other agreements
Starting with reference year 2021 two new regulations currently form the legal basis of SBS:
Regulation (EU) 2019/2152 repealing 10 legal acts in the field of business statistics (EBS Regulation), and
The Council Regulation No 58/97 has been amended three times: by Council Regulation No 410/98, Commission Regulation No 1614/2002 and European Parliament and Council Regulation No 2056/2002. As a new amendment of the basic Regulation it was decided to recast the Regulation No 58/97 in order to obtain a new "clean" legal text.
Loi du 10 juillet 2011 portant organisation de l’Institut national de la statistique et des études économiques on statistical confidentiality as it applies to the Luxembourgian Statistical System.
7.2. Confidentiality - data treatment
Primary rules
We apply the (n,k)-dominance rule, i.e. a cell is suppressed if n units separately or jointly dominate the total value of a cell by at least k%. The (n, k) parameters for Luxembourg are confidential. For any cells that are left after applying the sensitivity rule, a minimum frequency is applied. A cell is suppressed if there are less than n units in a given cell. The n parameter for Luxembourg is confidential.
The primary rules' underlying parameters are kept confidential because their disclosure could compromise the safety of the primary suppressed cells.
Secondary confidentiality rules
The secondary suppression is calculated by tau-Argus using the ‘Modular’ algorithm. Manual suppressions or cost adjustments are performed to adjust the secondary confidentiality pattern calculated by the software.
a) Secondary suppression within a table
• A cell is suppressed for secondary confidentiality if n units jointly or separately dominate the confidential subtotal by at least k%;
• special attention is paid to the impact of singletons, a risk which is in most cases directly addressed by the tau-Argus Modular algorithm;
• tau-Argus is set to minimise the cost when determining the secondary suppressed cells.
However, we also want to provide the user with relevant data, whether it is in terms of interpretation and/or availability of time series. Consequently, the cost minimisation can be overridden for economic and/or historical reasons.
b) Secondary suppression due to linked-table disclosure risks
A link is defined to exist between a cell sharing the same cell coordinates in two tables if an estimate for that cell based on the source table can be produced within p% range of the primary confidential cell's value of the target table. Most often, estimates based on the rule of three and linear interpolation, both of which are common user scenarios, are tested. Please note that p% only refers to the relationship between the dominance and p% thresholds and not to the p% sensitivity rule.
The following linked-table risks are addressed:
• historical disclosure (time dimension): no primary historically confidential cell should be compromised by disclosing the same cell for the current reference year. As long as there is a significant link with a prior year primary confidential data, a cell may not be disclosed for the current reference year.
• links to any other table sharing at least one dimension, including SBS tables by activty.
Other SDC policy considerations
The statistical confidentiality analyses are performed on the basis of turnover (shadow variable approach). The same disclosure pattern is then applied to all variables, including on the number of enterprises whenever necessary.
As a general principle, the NACE section level data, when not broken down by any other dimension than NACE and under the condition of being unfiltered, are not considered confidential, except if the section has a trivial breakdown. There can be other case-by-case exceptions to this general principle.
7.2.1. Confidentiality processing
Data treatment
Confidentiality rules applied
Yes
Threshold of number of enterprises (Number)
Confidential
Number of enterprises non confidential, if number of employments is confidential
Rule not applied
Dominance criteria applied
Yes
If dominance criteria applied specify the threshold (Number)
Confidential
Secondary confidentiality applied
Yes
Comment
-
8.1. Release calendar
Data are disseminated nationally but without any predefined release calendar.
8.2. Release calendar access
Not applicable.
8.3. Release policy - user access
All information accessible to the users are available in the published publications and in the published on-line databases.
Annual.
10.1. Dissemination format - News release
Currently, no news release for SBS.
10.2. Dissemination format - Publications
SBS publications are typically available in FR and some in EN language.
Any national micro-data access is governed by article 16 of the Law of 10 July 2011 on the organisation of the National Institute for Statistics and Economic Studies.
10.5. Dissemination format - other
Data are transmitted annually to Eurostat either to be used in European aggregates and for country comparisons.
10.6. Documentation on methodology
Methodological guidelines are generally in FR (ad-hoc publications or data publications), while definitions are embedded whenever available in the relevant tables (FR and EN)
As of 2015, the overall sampling error has become small to negligible because of the integration of a massive administrative accounting data source. Locally, higher sampling errors can still occur when both survey and administrative source coverage are low. Higher sampling errors are also still observed for certain variables which can currently not be measured via administrative sources, such as unpaid workers and variables which take into account the geographic or product dimension. In this case, the survey remains the only source.
Most measurement errors are in relation with NACE reclassifications. These can lead to local breaks in series when the NACE change was retroactively applied. In recent years, some globalisation phenomena observed through multinational enterprises have become the source of some significant interpretation difficulties and therefore potential measurement error. Finally, until reference year 2020, some investment variables were significantly understated absent any administrative source which would reliably measure investments in real estate assets and in intangible assets not subject to VAT.
As of 2019 reference year, a rolling revision policy has been introduced.
For further details, please refer to the sections 12 to 15.
12.1. Relevance - User Needs
External users: public and private research institutions, marketing companies, national central bank, lobby and policy groups, private users, university students, academic users and others. Most requested variables: “number of [units]”, “turnover”, “value-added” and “employment” by economic activity and occasionally by employment size class.
Internal users: national annual accounts, CIS-R&D statistics, ICT statistics, short-term statistics, foreign direct investment, internal research department, satellite accounts (culture, tourism). Internal users often need micro level data. SBS micro level data are mainly used as a direct data source for the production of other statistics (e.g. national annual accounts including the financial account, ICT, CIS-R&D) or to calculate index weights (e.g. short-term statistics). Other uses are quality checks, use of the data for sampling purposes, etc.
Internal users and business services. The geographical dimension in the national SBS survey is also a major national source for national accounts, not only for services companies but for production of services in general. The same source is used to compile SBS business services data.
Some data published nationally are different from European data
As of the revision from 2005 onwards in NACE Rev.2, the data are finally fully aligned with Eurostat with the following limits:
* For internal consistency reasons with the variables "Value-added" and "Production value", the national definition of turnover includes royalties invoiced for the period from 2005 to 2020.
* Not all variables are subject to national publication: e.g. subcontracting, investment by type of tangible asset, leasing, etc.
* Some variables are nationally published for all activities, whereas on the Eurostat website they are not: e.g. number of hours worked, changes in inventory, etc.
12.2. Relevance - User Satisfaction
No user satisfaction survey conducted in this statistical area.
12.3. Completeness
Unavailable breakdowns for water transport services (NACE Rev.2 H 50) - will be resolved as of SBS reference year 2024
Subdivisions by detailed activity (e.g. H 50.1 to 50.4) or by employment size class for water transport services, i.e. sea and coastal water transport, have been unavailable for many years in Luxembourg.
In Luxembourg, several hundreds of legal units have declared themselves as active in this activity. However, in substance only a certain subset of activities (e.g. logistics, management, leasing & renting, etc.) can be realised on or from the economic territory of Luxembourg, given the lack of access to any sea or the lack of direct access to any significant or relevant river.
The current figures rely on a branch estimate which was calculated on the basis of a dedicated analysis conducted in 2003. Unfortunately, its results are not available on the micro-data level, which explains that certain breakdowns are currently unavailable in the SBS tables. An update of this analysis was performed between 2017 and 2023, this time with the objective to reconsider the NACE and sector classification for each unit. This approach will allow to produce more detailed statistical outputs and thereby to satisfy the requirements of the SBS framework.
The updated analysis has obtained green light by Eurostat during 2025. Following the approval, the national business register has been updated. Results are expected to flow into SBS data as of reference year 2024.
13.1. Accuracy - overall
Sampling error is mainly relevant for small size classes but also more generally for certain characteristics (e.g. unpaid persons employed). This error has most often a local impact. Since 2015, the sampling error has been reduced due to the integration of administrative source on accounting data.
Coverage errors are relevant for activities which carry little to no employment and which are not or only partially covered by VAT data. Examples of such activities are real estate activities, parts of the financial sector and most of the health professions. The failure to identify special purpose entities early on is another potential source of coverage error. Overall, the impact of coverage errors is local but can be significant.
Unit non-response error is generally low due to imputation strategies. For certain activities (e.g. construction, real estate, health, financial), imputation is nonetheless more challenging and can thus generate locally significant misstatements.
Measurement errors pertain mainly but not only to errors in the NACE classification and can be of significant impact locally as well as globally. Errors due to the misinterpretation of or incomplete information on globalisation phenomena are rare but can have significant global impacts due to the bigger figures of multinational enterprises.
Data processing errors are rare but may have a significant impact when they go undetected. The aforementioned data processing and analysis procedures are normally sufficient but in the past a few rare cases of such errors slipped into published data.
Preliminary results for SBS are mostly burdened by undercoverage errors (insufficient VAT and accounting data available for units with no employment), data processing errors (due to imputation) and measurement errors (mainly due to NACE misclassifications). Quality of the variables Number of persons employed and Number of enterprises tend to be understated as a consequence in preliminary SBS.
13.2. Sampling error
Impact of sampling error
Sampling error has become less relevant as of reference year 2015 because of the integration of a new massive administrative data source. At a local level, especially when broken down both by activity and by employment size class, one may still observe higher sampling errors because not all firms are covered by the said administrative source.
Estimator description
The ratio estimator is used for grossing up. Please refer to section 18.5 for further details on grossing up procedures. The formula of the CV for the ratio estimator has been programmed in Stata implementing the analytic formulas described in the book “Techniques de sondage” by Pascal Ardilly (ISBN 10: 2-7108-0847-1).
Given the ratio R, the sampling variance has been estimated using the residuals (u) between the variable of interest (y) and the ancillary variable (x) :
with and ui = yi - R * xi
The CV has been calculated using the following formula:
Use of ancillary data
The CVs have been calculated for a given variable of interest with the corresponding ancillary variable.
The following variables of interest have been grossed up using the ancillary variable “turnover”: "Total net turnover" and "Value-added".
The following variables of interest have been grossed up using the ancillary variable “number of employees”: "Tangible gross investments" and "Number of persons employed".
Variable "Personnel costs" has been grossed up using the ancillary variable “personnel costs” available through administrative sources.
For the variable "Number of enterprises", the CV is zero, as it is available for every unit in the business register and thus does not need to be estimated.
For the variable "Number of employees", the CVs should be close to zero because, for the units not part of the survey, the administrative data source is used for hot-deck ratio imputation. For "Number of persons employed", this may not be the case because self-employed persons are not obtained from an administrative source.
Limits of the CV calculation
The CV has been calculated for every single cell, i.e. by activity broken down by employment size class. However, please note that the CV is not available for the following cells:
• zero value cells in the target population: the CV has been imputed to zero, even though technically its calculation is simply not applicable;
• cells with no unit or only one unit in the sample: the CV cannot be calculated and the corresponding cell's CV is flagged as unreliable. This can happen when the target population is small and more frequently at the employment size class level. Grossing-up strata may be less detailed than the "activity x employment size class" breakdown requested by Eurostat.
It should be noted that the CV for variables that can take negative values (e.g. variable "Value added") may not necessarily the most appropriate indicator to assess the sampling error.
13.3. Non-sampling error
1. Non-sampling error
Most measurement errors are in relation with NACE reclassifications and can lead to local, and more rarely global, breaks in series. Errors due to NACE account for the bulk of the documented breaks in the time series in Luxembourg's SBS.
In recent years, some globalisation phenomena observed through multinational enterprises have become the source of some very significant interpretation difficulties and therefore a potential source of error. This is mainly due to a growing importance of flows generated by multinationals as well as vague or absent methodology regarding the proper statistical treatment of these phenomena. As a consequence, Luxembourg set up a Large Cases Unit, which has been operational since 2018, to centralise information regarding multinationals with the objective to seek consistency across statistical domains regarding their treatment.
Massive imputation via administrative sources can be another source of measurement error: understated investment variables (until reference year 2020 included), slightly understated personnel costs (until reference year 2014 included), and misstated profit&loss variables as of the reference year 2015 (new data source). However, reasonable data processing and analysis procedures are in place to ensure that the most significant errors are captured before dissemination. Therefore, such errors most often bear only a local significance.
In case that such errors are observed posterior to SBS publication, impacted cells are subject to relevant quality flags (if available and meaningful, e.g. break in series, unreliable, contributes to EU total only, etc.) until the revision of the impacted reference year(s).
2. Measures to minimize non-response
Non-response concerns units for which any of the following characteristics applies:
units which have not responded. Every two months a written reminder is addressed to the units who have not responded. The third reminder is done by registered mail. We enforce statistical obligation on a case-by-case basis by filing a legal complaint against big units which have repeatedly failed to respond with usable data or at all;
the survey form data are not exploitable due to either inconsistent data or lack of information - the questionnaire design is reviewed every year to ensure that item non-response due to form design is minimal and does not transform into unit non-response;
units which have ceased their activity or which have been subject to restructuring (mergers, splits, etc.) during the reference year – for these units, data cannot be easily collected but have to be estimated or imputed in most cases;
units which cannot be contacted. The addresses for these units are checked manually using the phone book and the national Register of Natural and Legal Persons. Unit non response for this reason is usually low.
3. Imputation methods for dealing with non-response
As of reference year 2015, data from the Central Balance Sheet Office are used to impute units which are not part of the sample or which no recent survey data are available. Since revised 2021 data, records from the Central Balance Sheet Office are used to impute the investment variables when they are not already covered by the SBS survey.
Alternatively, non-responding units are imputed using the cold-deck ratio imputation. This method consists in applying an individual growth ratio expressed in terms of an administrative data indicator (turnover, number of employees, personnel costs) to the latest available survey data for the last 10 years. In some cases, mainly for bigger companies, the ratio is manually adjusted using annual business accounts available for the reference period. This provides an even more precise estimate. If the ratio is abnormally high (compared to other similar units in the stratum) or if there is a weak correlation between the administrative variable and the survey variable, this type of imputation is not performed.
Imputation procedures for employment variables are similar to the general approach. However, for variables "Number of full-time equivalent employees" and "Hours worked by employees", administrative source data as well as the variable "Number of employees" are used.
For investment variables of firms not covered by the aforementioned administrative accounting source, specialised VAT indicators are used to impute these variables.
If no historical data are available or if those data are deemed outdated, the units are grossed up using the same procedures as for units not covered by the sample or by imputed data.
4. Weighted non-response rate
The weighted unit response rate is weighted using the variable "Net turnover". The response rate is equal to 100% for the variables "Number of enterprises" and "Number of employees", as they are measured by administrative source. Overall, the weighted unit response rate is 92% in 2023 (2022: 96%). In some economic activities, the rate can be much lower, more particularly for activity branches in which there is a limited availability of business accounts.
Furthermore, the non-response rate itself can also be missing, i.e. if there was no unit in the sample for a given cell and/or no unit in the target population. It should be noted that :
• it is often not possible to use the same strata for estimation as those foreseen in the data transmission format. Given the fact that estimated values are imputed on a micro data level (imputation is done based on the relative importance of turnover for each unit), it is nonetheless possible to disclose the results according to the data transmission format ; • for the NACE groups H 50.1 to H 50.4, we do not use any micro data figures, please refer to section 12.3 for further details.
5. Bias from non-response and from the estimation method
Bias resulting from non-response
For the units for which administrative accounting data is available, the bias due to non-response is very small.
For the units to which the cold-deck ratio imputation method has been applied, the bias is significantly reduced when that ratio is adjusted with observations from the annual business accounts (if available).
If neither historical survey nor administrative accounting data are available for a given unit, the latter will be handled in the same way as any unit which is not included in the sample. The bias would then result from the estimation method.
Until reference year 2020 included, the investment variables suffered from a higher bias due to the fact that certain fixed assets classes (e.g. real estate, intangible assets produced in-house) could not be imputed by the VAT administrative source. As of reference year 2021 revised, the non-response bias has been significantly reduced thanks to the use of the administrative accounting source for these variables.
Bias resulting from the estimation method
According to the book reference mentioned in section 13.2, the ratio estimator is biased, the formula of the bias being complex but with an order of magnitude of 1/n. Consequently, the higher n (sample size), the smaller the bias. However, if n was small or if there was a weak linear correlation between the variable of interest and the auxiliary variable, the bias of the ratio estimator could be significant.
While the bias resulting from the estimation method remains unknown, the estimation method mainly concerns small units. Given the administrative accounting data source and the fact that mainly small units are concerned by estimation, we believe that it has a limited effect in the overall accuracy of the estimate.
6. Coverage error
Impact of coverage errors on the key statistics: medium.
7. Out-of-scope units
Definition
The most frequently observed type of out-of scope units are legal units which are incorporated or registered in Luxembourg but which at the same time do not have any non-financial economic activity in the Luxembourg economic territory (e.g. real-estate rental activities with buildings in foreign territories only, companies where the activity is done in foreign branches only, some activities related to shipping, captive special purpose entities, etc.). Another significant type of out-of-scope units relates to non-market activities.
Identification
Such units are identified and dealt with on a case-by-case basis by the staff involved in national accounts, SBS, business register and balance of payments. This kind of information is centralised through the statistical business register.
Estimated number of undetected units
It is not possible to provide an estimate of the number of undetected out-of-scope units still lingering in the SBS population. With the extension of the SBS tables in terms of activity coverage, more particularly section K, the risk of undetected out-of-scope units has however increased.
14.1. Timeliness
Time between end of reference period and national data dissemination: t+22 to t+24 months
14.2. Punctuality
SBS 2023 final data were delivered on time.
15.1. Comparability - geographical
Not applicable.
15.2. Comparability - over time
Length of comparable time series
1995 - 2002 (KAU concept)
2003 - 2009 (enterprise concept NACE Rev.1.1)
2005 - 2023 (enterprise concept NACE Rev.2)
Important events in the time series
A revision of SBS data series was completed in summer 2014 for the reference years 2005 to 2010 included. The revision was performed using NACE Rev.2 and included the revision of the profiling of some major players. The revision was significant due to the adaptation of the enterprise definition for some multinational enterprises and in general due to changes in NACE codes for enterprises.
As of 2012, the identification of the legal unit providing the activity support to the enterprise to which it belongs is allocated according to the contribution in terms of value-added of each legal unit composing the enterprise, in case the support unit allocated in the Business Register is too recent. The impact of this change is local and not global. For the same reference year, punctual, local and significant breaks in series are flagged accordingly in the tables. The reasons for the breaks are typically significant errors in the NACE codes for enterprises as well as significant measurement errors detected in hindsight.
As of 2014, the technical definition of the target population in terms of enterprises and KAUs has changed: KAUs without any activity support unit in the SBS target population as defined according to the enterprise concept are no longer part of the said population. The impact of this change in method had no significant impact but was important to ensure consistency with the financial sector.
As of 2015, Central Balance Sheet Office data are used to impute units which are not part of the sample or which no recent survey data are available. The impact of the data integration is an overall improvement of the sampling error, potentially traded for an increased measurement error at a local level. This integration lead to several local breaks in time series.
As of 2019 reference year, a rolling revision policy has been introduced. After the official production of reference year T (e.g. 2019) published during the year T+2 (e.g. 2021), a revision for the reference year T data is performed during T+3 (e.g. 2022). The impact of this revision not only removes local breaks in series due to temporary errors in NACE but also introduces a less desirable side-effect: due to the consideration of late VAT data during the revision, there is a potentially significant upward impact on the number of smaller active enterprises and the number of persons employed (excluding employees).
As of 2021 reference year, the SBS have been extended to NACE sections P, Q, R and K as well as NACE division S96, in conformity with the EBS regulation. These more recently added activity branches present certain challenges, most of which will be ironed out in the years to come. Furthermore, several alignments with business demography were performed.
As of 2021 revised, data from the Central Balance Sheet Office are used to impute the investment variables when they are not already covered by the SBS survey. This has lead to an overall break in series, even though the impact can be mainly observed in a few activity branches pertaining to construction, real estate and rental services.
15.2.1. Time series
Time series
First reference year available (calendar year)
1995
Calendar year(s) of break in time series
2005
Reason(s) for the break(s)
NACE Rev. 2 and data revision for 2005-2010
Length of comparable time series (from calendar year to calendar year)
1995 - 2002 (KAU concept)
2003 - 2009 (enterprise concept NACE Rev.1.1)
2005 - 2023 (enterprise concept NACE Rev.2)
Comment
-
15.3. Coherence - cross domain
Business demography
Timing differences are generally small. Most differences are permanent.
A project has started in Luxembourg in 2024 which seeks to have the population of both statistical domains converge. Some of these efforts have already made it into the population starting with reference year 2021. No revision of data for this purpose is planned for any year prior to 2021.
Thanks to a branch estimate, business demography used to more accurately reflect the number of enterprises than SBS for legal activities (NACE code 69.1) because the administrative sources are insufficiently detailed for SBS purposes and thus to maintain internal consistency between all the variables. Business demography has now abandoned this branch estimate to converge with SBS.
The financial activities K642 and K643 contain mainly captive financial institutions in Luxembourg. These extended economic activities in SBS-EBS have been aligned with business demography since reference year 2021 revised.
In trade activities, SBS took a different historical path than business demography: the latter assumed that some very small units should be dismissed as inactive, whereas in SBS the said units would be kept in the target population. This issue has been resolved.
For the number of persons employed, the issue under investigation is due to independent workers, for which there is currently a lack of access on complete administrative source data. Furthermore, depending on the interpretation of these data, this difference could lead to a non-negligible revision of the number of employees in SBS and in business demography.
For health professions, STATEC lacks access to administrative source data (social security, income tax) which would enable to calculate reliable results based on a bottom-up approach. In business demography, this activity branch is currently based on a branch esimate, while in SBS, the available, albeit incomplete, micro data are used instead. The branch estimate cannot be used in SBS because it only covers the number of enterprises and employment variables. Therefore, this difference remains under investigation.
Prodcom
Not available in Luxembourg.
National accounts
Consistency has been officially documented for the variables "Turnover", "Value of output" and "Number of persons employed". Generally, differences arise from diverging methodologies. While SBS is generally based on a bottom-up approach, consisting in aggregating business accounts figures, national accounts integrate other data sources at a more aggregated level (e.g. taxes, other sectors, illegal activities, etc.) - such integration requires the use of balancing procedures, which results in differences with SBS. Timing differences are also possible but generally of low impact.
Furthermore, it appears that "Number of hours worked by employees" is generally lower in national accounts figures than for SBS or LCS.
Short-term statistics
No efforts have been invested so far in analysing the potential or actual data inconsistencies between SBS and STS. However, the latter uses SBS data by KAU for weighting purposes.
Labour Cost Survey (LCS) for wages and salaries per employee
If we consider only the population of enterprises employing at least 10 persons and only those economic activities which are covered by both statistics at the same time, the figures are similar.
15.4. Coherence - internal
Internal inconsistencies stem most often from rounding errors.
Burden on enterprises
With the advent of the revised standard accounting chart in 2020, the SBS survey has finally been abolished for smaller firms since reference year 2021. Data collection for these units is now mostly based on the administrative accounting sources (mainly Central Balance sheet Office). This has dramatically reduced the statistical reporting burden on smaller businesses.
For medium-sized and large enterprises, the SBS survey remains in place to deal with certain specific issues, e.g. product breakdown of flows, geographical breakdown of flows, investment variables, MNEs, branches abroad, local units, ultimate control and so forth. Burden due to the SBS survey is nevertheless minimal (1-2 hours in average per enterprise):
A firm can send their raw data (e.g. trial balance, business accounts, fixed assets table, etc.) to STATEC for processing by specialised staff;
A firm can benefit from a significant reduction of the burden in case that it files their data according to the standard accounting chart.
In case that an enterprise does not make use of any such facilities, the average response burden is 8 hours in average to fill in the complete survey form.
17.1. Data revision - policy
As of reference year 2019, a rolling revision policy has been introduced for SBS. This decision was taken to the minimise the need for costly major revisions.
After the official production of reference year T (e.g. 2019) published during the year T+2 (e.g. 2021), a revision for the reference year T data is performed during T+3 (e.g. 2022). The impact of this revision does not only remove any local breaks due to temporary errors in NACE but it also introduces a less desirable side-effect: due to the consideration of late VAT data, there is a significant upward impact on the number of active enterprises (mainly very small entities) and the number of persons employed (not employees).
This effect does also occur with a major revision, only that in this case, several years are revised at the same time instead of a single reference year. Furthermore, the aforementioned effect has been recently amplified by the fact that official deadlines for filing VAT returns have been increased by another two months ever since Covid-19.
Statistical disclosure control is still a considerable bottleneck to any revision policy, given the detailed breakdowns in SBS and the links with other domains (IFATS, ICT, CIS, BERD). However, while SBS are revised, the other statistical domains will most often not follow due to resources constraints. Consequently, cross-domain coherence is impacted by this revision policy.
The latest major revision was undertaken in 2014 for the data series 2005 - 2011 included. There are no plans to conduct any other major revision due to resources constraints.
17.2. Data revision - practice
Methods for compiling preliminary data
Since reference year 2016, Central Balance Sheet Office data for the current reference year are used when available. Before 2016 or in case of no such administrative data, preliminary data series are based on estimates which consist, for the vast majority of cases, of adjusted survey data from the reference year t-1.
The adjustment is possible due to the use of up-to-date administrative data sources, using mainly the cold-deck ratio imputation as described in section 13.3. Units for which there is no t-1 survey data are grossed up using the estimation method described in section 18.5.
Comments on the differences between final and preliminary estimates
There is a consistent underestimation of preliminary data compared to final data. This is because the VAT administrative data are not complete at t+9 or t+10 months, so that the preliminary target population is potentially incomplete for both self-employed businesses and businesses without any employees.
The late availability is explained by the final administrative deadline for companies to file their annual VAT declaration (set at t+10 to t+12 months). An adjustment is performed for businesses who have not yet filed their VAT declaration at the compilation date but who employ more than 0 employees in average during the reference year, which reduces the impact.
- Number of persons employed
In 2023, the preliminary number of persons employed for the total business economy was understated, the final figure being 0.3% above the preliminary figure (2022: 0.2%). For 2023, this is in line with expectations, given the incomplete target population and thus an incomplete number of "unpaid" persons employed.
At the 3-digit NACE level, the relative absolute mean revision was 1.4% in 2023 (2022: 2.6%). This is mainly explained by the aforementioned reasons as well as by changes in NACE codes for some businesses between the preliminary and the final data productions.
- Turnover
In 2023, the preliminary turnover for the total business economy was understated (2022: overstated), the final figure being 0.9% above the preliminary figure (2022: 1% below the preliminary figure). In addition to the incomplete target population, the difference is also explained by the structural differences between turnover as per VAT and turnover as per business accounts. Only some of these differences can be smoothened at the preliminary production stage, more particularly through ad-hoc editing and ratio imputation.
At the 3-digit NACE level, the relative absolute mean revision was 3.1% in 2023 (2022: 6.9%). This indicator usually emphasizes the explanations here above and is mainly explained by the aforementioned reasons as well as by changes in NACE codes for some businesses between the preliminary and the final data productions.
18.1. Source data
Statistical survey combined with administrative sources
The annual structural business survey used to be at the heart of the data collection. While this is still true today for medium-size and large firms, for smaller entities, the administrative accounting sources (mainly Central Balance sheet Office) have progressively taken over since reference year 2015.
Even with the partial shift from survey to administrative sources, the data collection still requires a sample which is based on a stratified random sampling design. With the extension of the activity coverage as of reference year 2021, the sampling strategy was revised. Using strata based on the number of employees and turnover applied on the population frame, a random stratified sample is drawn and then divided into two subsamples:
* an exhaustive survey subsample: any legal units employing either more than 50 employees or having declared a turnover excluding VAT of at least 12 million EUR per annum are selected every year. For certain activities in the financial sector, the thresholds are increased for survey cost reasons. Any legal units linked to the aforementioned units (e.g. group or enterprise links) are also selected to form part of the survey every year. To cover the needs of national accounts and SBS, the survey sample size is roughly equal 3000 reporting units.
* a random administrative accounting source subsample: any legal units having both less than 50 employees and a turnover of less than 12 million EUR are drawn randomly by stratum and exhaustively when the stratum only consists of singletons. Instead of being surveyed, these units are later on imputed using detailed administrative accounting data available for the reference year. The sample design allows for the possibility to use these units for handling non-response in the administrative accounting source, that is units which have not yet reported their accounting data at the moment of statistical production. The sample size is roughly equal to 7000 reporting units.
Administrative accounting data may be available for any firm in the population but outside of the aforementioned sample. When such data are available, these units, which are not part of the sample and which can therefore only represent themselves in the total population, are removed from the subpopulation to gross up, thus contributing to the reduction of the sampling variance due to grossing up.
Credit establishments and insurance companies are measured entirely through administrative sources (prudential reporting) and only abide by the guidelines here above for investment variables, which are entirely measured by survey for this specific sector.
The stratification used in the sample design does not take into account the size classes defined in the transmission format of the EBS SBS regulation. However, mass imputation procedures exist on a micro-data level, so that data can be broken down according to any spanning variable defined a posteriori, albeit with an increased risk of bias:
* since 2015, detailed accounting data from the Central Balance Sheet Office have been used to impute units which are not part of the sample or which no recent survey data are available (with a sample weight of 1) - this source covers balance sheet and profit & loss. In recent years, the data source accounts for more than half of the SBS population;
* since 2005, social security data have been used to impute the number of employees, personnel costs and number of hours worked by employees;
* detailed VAT data are used to impute investment variables, unless the latter can be derived from the administrative accounting data (since reference year 2021 revised);
* VAT and social security key indicators are used to impute non-respondent units using a cold-deck ratio imputation method.
Data sources used for the population frame or target population
The statistical business register is the primary source for building the target population. The said register is enriched by key data from social security and VAT, and since 2019 from the administrative accounting data. These data are used to determine the activity status of any enterprise. Only active units are retained. There is no threshold on employment and turnover, except that either has to be positive for the reference year in question.
In addition, for units having no employment and not covered by either VAT or accounting data source, the survey helps to identify a few active units. They are added to the population frame.
NACE classification
The difference between principal and secondary activities is directly available in the business register. The approach to identify principal activities is the top-down approach. Stability rules are in place to avoid yearly shifting between principal and secondary activities.
The update frequency of the business register is daily. However, for SBS purposes the extract of the business register is frozen at a given date. From that moment on, changes in NACE are only performed on an ad hoc basis and through a dedicated working area.
Relationship between the reporting unit and the enterprise
In the SBS survey, the reporting unit is the legal unit. However, for a very few legal units, the data are collected separately for the economic subdivisions of the legal unit (kind-of-activity units). Moreover, local unit data are collected at legal unit level for units being part of the SBS survey. In the administrative sources, the reporting unit is the legal unit.
Finally, the statistical unit "enterprise" can be a legal unit or a combination of legal units. Enterprises which are formed by a group of legal units are not the general case in Luxembourg but their occurrence is still significant, in particular due to many legal units specialized in ancillary activities for other legal units belonging to the same enterprise group.
18.1.1. Data sources overview
Data sources overview
Survey data
Yes
VAT data
Yes
Tax data
No
Financial statements
Yes
Other sources, please specify
Social security, Central Balance Sheet Office, Prudential reporting data for the financial sector
Comment
-
18.2. Frequency of data collection
Annual data collection.
18.3. Data collection
Survey forms are sent out by postal mail due to the complexity of the forms. Forms are organised by economic activity, with a total of 7 customised survey forms.
Respondents have the following response options:
1. fill in the complete survey form; 2. providing all the necessary financial reporting information to STATEC for further processing - electronically or by paper; 3. fill in parts of the survey form and file the standard chart of accounts for the said reference year.
For procedures pertaining to minimising non-response, please refer to chapter 13.3.
Administrative data are accessed mainly through the business register. There is no direct or live access to any administrative database other than the Central Balance Sheet Office data. Some administrative sources are available through flat files (e.g. prudential reporting by credit institutions).
18.4. Data validation
Survey data are subject to an in-depth validation programme. Administrative source data are checked for plausibility for every unit in the sample and on a case-by-case basis with annual business accounts (if available at the Register of Commerce). For the units not covered by the survey, outlier / leverage point tests are performed to avoid any negative impacts on the ratio estimation.
Type of controls
The test environment underlies an objective-driven risk management strategy. This ensures that the survey data comply with the pre-defined quality standard. The following documentation (in French) describes an old version of framework used to cover non-sampling errors for the survey reference year 2005, i.e. in the context of the old regulatory framework.
There is no updated version of the report, for it is was published as a working paper and thus is not an official methodological document by STATEC. However, it provides an idea of the type of control environment deployed in the area of SBS survey data. PDF Economie et statistiques 29/2009 - Statistiques - Luxembourg (public.lu)
The test environment covers both micro-data and tabular data and consists in control activities which cover
* completeness (data integrity rules); * validity (internal consistency); * plausibility, coherence and comparability; * outlier and leverage point detection; * confidentiality.
Errors in the administrative sources
Error checking activities in the administrative sources consist in the following:
* analysis of the correlation between survey and administrative variables; * analysis of births and deaths of significant units; * detection of out-of-scope units; * comparability in time and NACE classification of enterprise units (enterprise concept); * outlier detection; * identification of merger and acquisitions to minimise the risk of double counting; * automatic validation procedures for the standard chart of accounts data (as of 2015).
18.5. Data compilation
Unit non-response imputation
Please refer to section 13.
Item non-response imputation
Given that SBS data are above all quantitative and that they also serve the needs of national accounts, it is very difficult to identify item non-response. This is in particular true for units who are included only once in the sample in a given time series. For the bigger companies, it is possible to follow the reporting structure over a larger time period and thus to identify item non-response in an easier way. Item non-response is therefore dealt with on a case-by-case basis during editing procedures.
Missing or erroneous information in the administrative source
Administrative data can be systematically missing or punctually missing.
The risk of systematically missing administrative data is significantly higher in a few very specific financial activities (subject to prudential reporting but insufficiently detailed) and for health professions (VAT not applicable, no obligation to file any financial statements, no access to revenue tax data). In such cases, it is often not possible to fill the gaps with survey data because the survey requires the units to be active in terms of administrative source indicators (e.g. VAT, employment, accounting records, etc.).
In case of punctually missing or erroneous administrative data, adjustments are performed in a dedicated working area. For the administrative accounting data source (available as of 2015), any missing data is imputed using either cold-deck ratio imputation or hot-deck ratio imputation (grossing up).
Grossing up
When grossing up survey data, we always take into account ancillary data available in the administrative sources, i.e. the ancillary variables “turnover” and “number of employees”, and not only the sample design. The aforementioned ancillary variables most often have a linear correlation with the variables of interest in SBS. Consequently, the ratio estimator is used for grossing up.
With the variable of interest being available only for the sample (y) and with the ancillary variable being available both for the sample (x) and the SBS target population (X), the ratio estimator of the variable of interest , expressed as an average, can be written:
The ratio R has been formulated in the following way:
If for a given stratum no unit is available in the sample, i.e. neither for the historical periods nor for the reference period, the units in this stratum are grouped together with another stratum for which sample data are available and are then grossed up.
Variables "Number of enterprises", "Personnel costs", "Wages", "Social security charges", "Number of employees", "Number of full-time equivalent employees" and "Number of hours worked by employees" are directly derived from administrative source data and therefore do not need to be grossed up (as from reference year 2009). If prior year survey data are available, a cold-deck ratio imputation is performed – this significantly reduces the bias in case there are permanent differences between the admin source and the survey data for a given unit. For the other units, administrative data are simply pasted into the data set.
Please also refer to section 13.
18.6. Adjustment
If the reference period of a company differs from the calendar year, there is no correction to bring it in accordance with the statistical reference period.
For each company with a different financial year than the calendar year, we take a decision regarding the SBS reference period. Normally, this decision is taken in such a way that at least 6 full months of the financial year for a given company are included in the corresponding SBS reference period. Once that decision is taken, it is maintained every subsequent year for comparability reasons.
No further comments.
Structural business statistics (SBS) describes the structure, conduct and performance of economic activities, down to the most detailed activity level (several hundred economic sectors). SBS covers all activities of the business economy with the exception of agricultural activities, public administration and (largely) non-market services such as education and health. Main characteristics (variables) of the SBS data category:
"Business demographic" variables (e.g. Number of active enterprises)
"Output related" variables (e.g. Net turnover, Value added)
"Input related" variables: labour input (e.g. Number of employees and self-employed persons, Hours worked by employees); goods and services input (e.g. Purchases of goods and services); capital input (e.g. Gross investments)
Business services statistics (BS) collection contains harmonised statistics on business services. From 2008 onwards BS become part of the regular mandatory annual data collection of SBS. The BS’s data requirement includes variable “Turnover” broken down by products and by type of residence of client.
The annual regional statistics collection includes three characteristics due by NUTS-2 country region and detailed on NACE Rev. 2 division level (2-digits).
19 August 2025
SBS constitutes an important and integrated part of the new European Business Statistics Regulation N° 2152/2019
units with a non-zero value of turnover, non-zero value of operating costs or non-zero employees;
units which are active according to the SBS survey and not properly recorded in the administrative sources (e.g. VAT exempt units without employment and not having filed their detailed financial statements yet);
The market status of a unit is defined in terms of the national accounts institutional sectors. Sectors 12.7, 13 and 15 are excluded from the target population. The following units are specifically excluded:
temporary partnerships;
private persons producing energy using photovoltaic installation;
artificial subsidiaries and other special purpose entities dealing almost exclusively with group affiliates.
There are no exclusions in terms of NACE. However, branch H.50 (water transport) is only available as a branch estimate and not as micro-data. Consequently, the size class dimension is not reliable for this activity branch.
Luxembourg economic territory.
2023
The reference year corresponds with the calendar year.
For each company with a different financial year than the calendar year, we take a decision regarding the SBS reference period. Normally, this decision is taken in such a way that at least 6 months of the financial year for a given company are included in the corresponding SBS reference period. Once that decision is taken, it is maintained every subsequent year for comparability reasons.
Sampling error is mainly relevant for small size classes but also more generally for certain characteristics (e.g. unpaid persons employed). This error has most often a local impact. Since 2015, the sampling error has been reduced due to the integration of administrative source on accounting data.
Coverage errors are relevant for activities which carry little to no employment and which are not or only partially covered by VAT data. Examples of such activities are real estate activities, parts of the financial sector and most of the health professions. The failure to identify special purpose entities early on is another potential source of coverage error. Overall, the impact of coverage errors is local but can be significant.
Unit non-response error is generally low due to imputation strategies. For certain activities (e.g. construction, real estate, health, financial), imputation is nonetheless more challenging and can thus generate locally significant misstatements.
Measurement errors pertain mainly but not only to errors in the NACE classification and can be of significant impact locally as well as globally. Errors due to the misinterpretation of or incomplete information on globalisation phenomena are rare but can have significant global impacts due to the bigger figures of multinational enterprises.
Data processing errors are rare but may have a significant impact when they go undetected. The aforementioned data processing and analysis procedures are normally sufficient but in the past a few rare cases of such errors slipped into published data.
Preliminary results for SBS are mostly burdened by undercoverage errors (insufficient VAT and accounting data available for units with no employment), data processing errors (due to imputation) and measurement errors (mainly due to NACE misclassifications). Quality of the variables Number of persons employed and Number of enterprises tend to be understated as a consequence in preliminary SBS.
Number of enterprises and number of local units are expressed in units.
Monetary data are expressed in millions of €.
Employment variables are expressed in units.
Per head values are expressed in thousands of € per head.
Ratios are expressed in percentages.
Unit non-response imputation
Please refer to section 13.
Item non-response imputation
Given that SBS data are above all quantitative and that they also serve the needs of national accounts, it is very difficult to identify item non-response. This is in particular true for units who are included only once in the sample in a given time series. For the bigger companies, it is possible to follow the reporting structure over a larger time period and thus to identify item non-response in an easier way. Item non-response is therefore dealt with on a case-by-case basis during editing procedures.
Missing or erroneous information in the administrative source
Administrative data can be systematically missing or punctually missing.
The risk of systematically missing administrative data is significantly higher in a few very specific financial activities (subject to prudential reporting but insufficiently detailed) and for health professions (VAT not applicable, no obligation to file any financial statements, no access to revenue tax data). In such cases, it is often not possible to fill the gaps with survey data because the survey requires the units to be active in terms of administrative source indicators (e.g. VAT, employment, accounting records, etc.).
In case of punctually missing or erroneous administrative data, adjustments are performed in a dedicated working area. For the administrative accounting data source (available as of 2015), any missing data is imputed using either cold-deck ratio imputation or hot-deck ratio imputation (grossing up).
Grossing up
When grossing up survey data, we always take into account ancillary data available in the administrative sources, i.e. the ancillary variables “turnover” and “number of employees”, and not only the sample design. The aforementioned ancillary variables most often have a linear correlation with the variables of interest in SBS. Consequently, the ratio estimator is used for grossing up.
With the variable of interest being available only for the sample (y) and with the ancillary variable being available both for the sample (x) and the SBS target population (X), the ratio estimator of the variable of interest , expressed as an average, can be written:
The ratio R has been formulated in the following way:
If for a given stratum no unit is available in the sample, i.e. neither for the historical periods nor for the reference period, the units in this stratum are grouped together with another stratum for which sample data are available and are then grossed up.
Variables "Number of enterprises", "Personnel costs", "Wages", "Social security charges", "Number of employees", "Number of full-time equivalent employees" and "Number of hours worked by employees" are directly derived from administrative source data and therefore do not need to be grossed up (as from reference year 2009). If prior year survey data are available, a cold-deck ratio imputation is performed – this significantly reduces the bias in case there are permanent differences between the admin source and the survey data for a given unit. For the other units, administrative data are simply pasted into the data set.
Please also refer to section 13.
Statistical survey combined with administrative sources
The annual structural business survey used to be at the heart of the data collection. While this is still true today for medium-size and large firms, for smaller entities, the administrative accounting sources (mainly Central Balance sheet Office) have progressively taken over since reference year 2015.
Even with the partial shift from survey to administrative sources, the data collection still requires a sample which is based on a stratified random sampling design. With the extension of the activity coverage as of reference year 2021, the sampling strategy was revised. Using strata based on the number of employees and turnover applied on the population frame, a random stratified sample is drawn and then divided into two subsamples:
* an exhaustive survey subsample: any legal units employing either more than 50 employees or having declared a turnover excluding VAT of at least 12 million EUR per annum are selected every year. For certain activities in the financial sector, the thresholds are increased for survey cost reasons. Any legal units linked to the aforementioned units (e.g. group or enterprise links) are also selected to form part of the survey every year. To cover the needs of national accounts and SBS, the survey sample size is roughly equal 3000 reporting units.
* a random administrative accounting source subsample: any legal units having both less than 50 employees and a turnover of less than 12 million EUR are drawn randomly by stratum and exhaustively when the stratum only consists of singletons. Instead of being surveyed, these units are later on imputed using detailed administrative accounting data available for the reference year. The sample design allows for the possibility to use these units for handling non-response in the administrative accounting source, that is units which have not yet reported their accounting data at the moment of statistical production. The sample size is roughly equal to 7000 reporting units.
Administrative accounting data may be available for any firm in the population but outside of the aforementioned sample. When such data are available, these units, which are not part of the sample and which can therefore only represent themselves in the total population, are removed from the subpopulation to gross up, thus contributing to the reduction of the sampling variance due to grossing up.
Credit establishments and insurance companies are measured entirely through administrative sources (prudential reporting) and only abide by the guidelines here above for investment variables, which are entirely measured by survey for this specific sector.
The stratification used in the sample design does not take into account the size classes defined in the transmission format of the EBS SBS regulation. However, mass imputation procedures exist on a micro-data level, so that data can be broken down according to any spanning variable defined a posteriori, albeit with an increased risk of bias:
* since 2015, detailed accounting data from the Central Balance Sheet Office have been used to impute units which are not part of the sample or which no recent survey data are available (with a sample weight of 1) - this source covers balance sheet and profit & loss. In recent years, the data source accounts for more than half of the SBS population;
* since 2005, social security data have been used to impute the number of employees, personnel costs and number of hours worked by employees;
* detailed VAT data are used to impute investment variables, unless the latter can be derived from the administrative accounting data (since reference year 2021 revised);
* VAT and social security key indicators are used to impute non-respondent units using a cold-deck ratio imputation method.
Data sources used for the population frame or target population
The statistical business register is the primary source for building the target population. The said register is enriched by key data from social security and VAT, and since 2019 from the administrative accounting data. These data are used to determine the activity status of any enterprise. Only active units are retained. There is no threshold on employment and turnover, except that either has to be positive for the reference year in question.
In addition, for units having no employment and not covered by either VAT or accounting data source, the survey helps to identify a few active units. They are added to the population frame.
NACE classification
The difference between principal and secondary activities is directly available in the business register. The approach to identify principal activities is the top-down approach. Stability rules are in place to avoid yearly shifting between principal and secondary activities.
The update frequency of the business register is daily. However, for SBS purposes the extract of the business register is frozen at a given date. From that moment on, changes in NACE are only performed on an ad hoc basis and through a dedicated working area.
Relationship between the reporting unit and the enterprise
In the SBS survey, the reporting unit is the legal unit. However, for a very few legal units, the data are collected separately for the economic subdivisions of the legal unit (kind-of-activity units). Moreover, local unit data are collected at legal unit level for units being part of the SBS survey. In the administrative sources, the reporting unit is the legal unit.
Finally, the statistical unit "enterprise" can be a legal unit or a combination of legal units. Enterprises which are formed by a group of legal units are not the general case in Luxembourg but their occurrence is still significant, in particular due to many legal units specialized in ancillary activities for other legal units belonging to the same enterprise group.
Annual.
Time between end of reference period and national data dissemination: t+22 to t+24 months
Not applicable.
Length of comparable time series
1995 - 2002 (KAU concept)
2003 - 2009 (enterprise concept NACE Rev.1.1)
2005 - 2023 (enterprise concept NACE Rev.2)
Important events in the time series
A revision of SBS data series was completed in summer 2014 for the reference years 2005 to 2010 included. The revision was performed using NACE Rev.2 and included the revision of the profiling of some major players. The revision was significant due to the adaptation of the enterprise definition for some multinational enterprises and in general due to changes in NACE codes for enterprises.
As of 2012, the identification of the legal unit providing the activity support to the enterprise to which it belongs is allocated according to the contribution in terms of value-added of each legal unit composing the enterprise, in case the support unit allocated in the Business Register is too recent. The impact of this change is local and not global. For the same reference year, punctual, local and significant breaks in series are flagged accordingly in the tables. The reasons for the breaks are typically significant errors in the NACE codes for enterprises as well as significant measurement errors detected in hindsight.
As of 2014, the technical definition of the target population in terms of enterprises and KAUs has changed: KAUs without any activity support unit in the SBS target population as defined according to the enterprise concept are no longer part of the said population. The impact of this change in method had no significant impact but was important to ensure consistency with the financial sector.
As of 2015, Central Balance Sheet Office data are used to impute units which are not part of the sample or which no recent survey data are available. The impact of the data integration is an overall improvement of the sampling error, potentially traded for an increased measurement error at a local level. This integration lead to several local breaks in time series.
As of 2019 reference year, a rolling revision policy has been introduced. After the official production of reference year T (e.g. 2019) published during the year T+2 (e.g. 2021), a revision for the reference year T data is performed during T+3 (e.g. 2022). The impact of this revision not only removes local breaks in series due to temporary errors in NACE but also introduces a less desirable side-effect: due to the consideration of late VAT data during the revision, there is a potentially significant upward impact on the number of smaller active enterprises and the number of persons employed (excluding employees).
As of 2021 reference year, the SBS have been extended to NACE sections P, Q, R and K as well as NACE division S96, in conformity with the EBS regulation. These more recently added activity branches present certain challenges, most of which will be ironed out in the years to come. Furthermore, several alignments with business demography were performed.
As of 2021 revised, data from the Central Balance Sheet Office are used to impute the investment variables when they are not already covered by the SBS survey. This has lead to an overall break in series, even though the impact can be mainly observed in a few activity branches pertaining to construction, real estate and rental services.